







Cross Validation is a concept which we can use to validate different models and find the best tuning parameters.
At times, in machine learning we always face the questions like :
- How do we decide which model to use?
- Which model will be more efficient?
- Which parameters are the best for a model?
Cross Validation is a concept which we can use to validate different models and find the best tuning parameters.
How does cross validation works?
- First, we divide our dataset in k number of partitions called folds
- Then we use one of the folds as testing set and remaining folds as training set
- We calculate the testing accuracy and repeat the steps such that we have used each fold as testing set and others as training set
- After that we take the average of these accuracy and estimate the combined accuracy by finding the mean
- We do the same for multiple models and pick up the best model for our use case

(Figure showing cross validation with 5 folds)
Now, let’s see this with an example where we use iris dataset to predict the flower and see if KNN model is better or logistic regression is a better model to go for.
- Importing the python modules

- Loading the iris dataset
Iris dataset is a dataset which contains various features like sepal length/width and petal length/width mapped with a target value of the flower. So basically, here we will be predicting the variety of flower based on it’s characteristics.

- Initializing the features X and target y

- The X is a feature matrix which contains a list of features our model needs to get trained. These are independent variables.
The y is the target variable which we want to predict and it is dependent on X. In this example, y can be either of (0,1,2) representing a variety of flower which our model will predict. - Creating the models and validating the accuracy
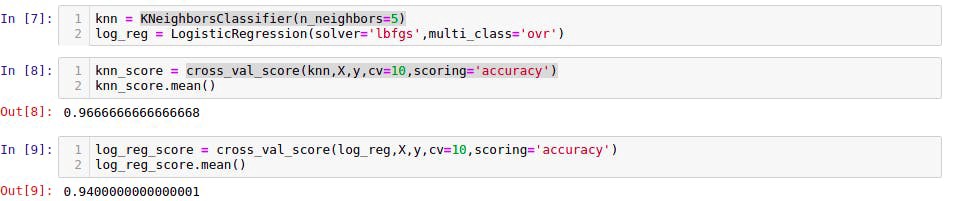
- Here our aim is to create two models Logistic Regression and K-Nearest Neighbors and validate them in order to chose the best among them.
We have used 10 fold cross validation(cv=10) to validate both the models.
The KNN algorithm (96.66%) is slightly better than logistic regression (94%) after the evaluation so we would be using that to build our machine learning model.
Finding the best tuning parameter
We can find the best tuning parameters using cross validation. Let’s try to find the most optimal value of k to tune the K-Nearest Neighbours algorithm.
- Firstly, we initialise a range of k values from which we want to chose the most optimal one.
- Then we find the mean accuracy for each run using a different k and chose the best value for k.

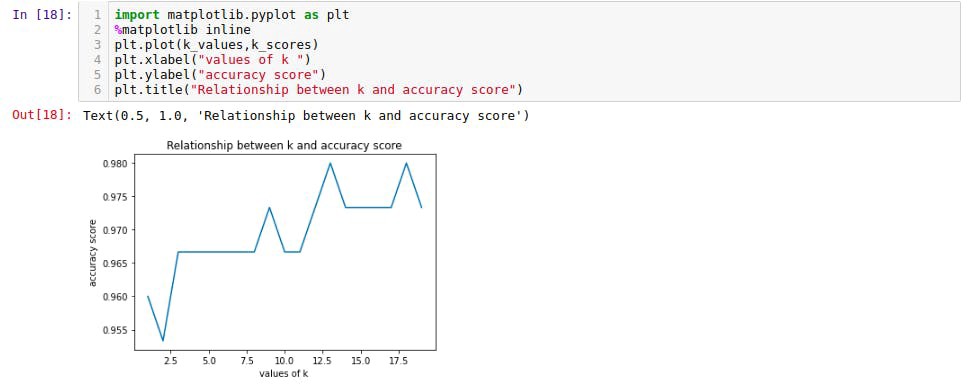
In the above example we want to chose the best value of k (1 to 20) and their performance accuracy are stored in k_scores list.
- This plot shows the relationship between k and accuracy score and how k=12 can be the most optimal value of k with 98% accuracy and k=1 can be least optimal value with 95% accuracy.
Conclusion
After validating our dataset with cross validation we would want to use KNN Algorithm to create our model with the best value of the tuning parameter k to be 12.
This is an introduction to machine leaning model validation and I’ll be posting many more content of machine learning and data science.
Thanks for reading , I’ll be posting more contents related to this. :)
Share with your friends and followers
Start blogging about your favorite technologies, reach more readers and earn rewards!
Join other developers and claim your FAUN account now!


User Popularity
13
Influence
1k
Total Hits
1
Posts

Read, Learn, Know, Teach
Hand curated newsletters for Developers, private Slack with like minded people, podcasts, job offers, news and more!

Only registered users can post comments. Please, login or signup.