







GIT — is a powerful tool for collaborating with the team and storing work that can be easily replayed in time. However, for a sad reason, a lot of people use the GUI tool for interacting with it and can’t uncover its full potential of this tool. Like in a famous meme people learn only to commit and push and if something happened, they prefer to reload copies except to solve problems. (In all cases it’s not the optimal way)

XKCD Common usage of git tool.
Requirements
- CLI that support UNIX styles commands
- git version > 2.0 (For me current version is 2.34.0)
- github.com account
Why use the command line?
All GUI tools for git have been built on top of CLI, also nowadays they’ve become very rich, but they lack functionality from the original CLI. For simple tasks it’s not a big deal, but for complicated one missing functionality start to become vital.
GUI can sometimes create a layer of abstraction for the user, that becomes only available only in this proprietary tool putting boundaries on choosing software freely.
Last, but not least CLI commands can be automatized using bash on your demand. (Combining several commands you can gain a stunning result) With GUI — you’re fully dependent on vendor updates.
What is GIT?
GIT — Distributed Version Control System
Let’s unpack this. Distributed — means that storing of data is the responsibility of several computers, not a single one. For example, the server, our computer and collaborator Bob’s computer. Distributing doesn’t mean that our data will be synchronized.
Version Control System — every object (in our case file) have an established state in time (version) and we can manage this state and go back and forward replaying it. (control system).
How does GIT store information?
- At its core, GIT is like a key-value store.
- The Value = Data
- The Key = Hash of data
- Having keys, you can retrieve files.
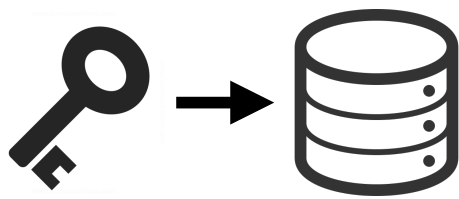
Key to content transformation
The key — SHA1
- Cryptographic hash function.
- Given a piece of data, it produces a 40-digit hexadecimal number.
- This value always is the same if the given input is the same.
The value — BLOB
GIT stores the compressed data in a blob, along with metadata in a header:
- identifier blob
- size of content
\0delimiter- content

Schema of the git value
This picture can be misleading, so you should understand that these four blocks are sequentially and do not lie on a disk as presented in the mnemonic picture.
Under the hood — GIT Hash-Object
Let’s ask git for SHA1 of content
Result
Let’s try with metadata
Result
It’s a match with the previous result
Where does GIT store its data?
.git the directory contains info about the repository
We need more info
The block lacks information:
- filenames
- directory structure
Git manages this information in a tree.
Tree
A tree contains pointers (using SHA1):
- to BLOBs
- to trees
and metadata:
- type of pointer (blob or tree)
- filename or folder name
- mode (executable file, symbolic link, …)

Example of the tree structure
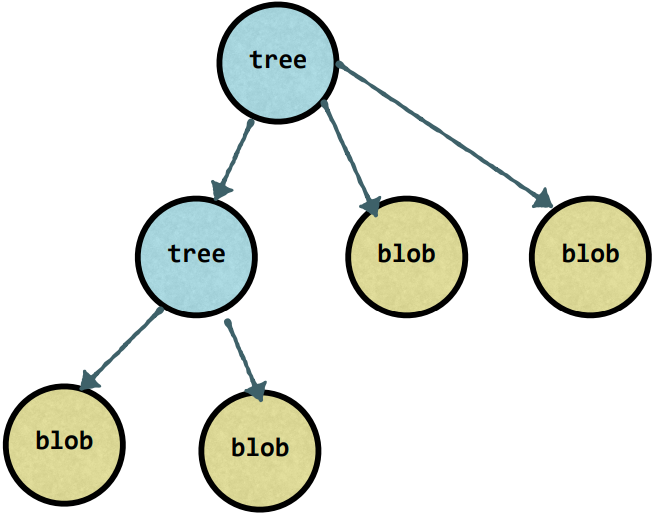
Trees point to blobs and trees
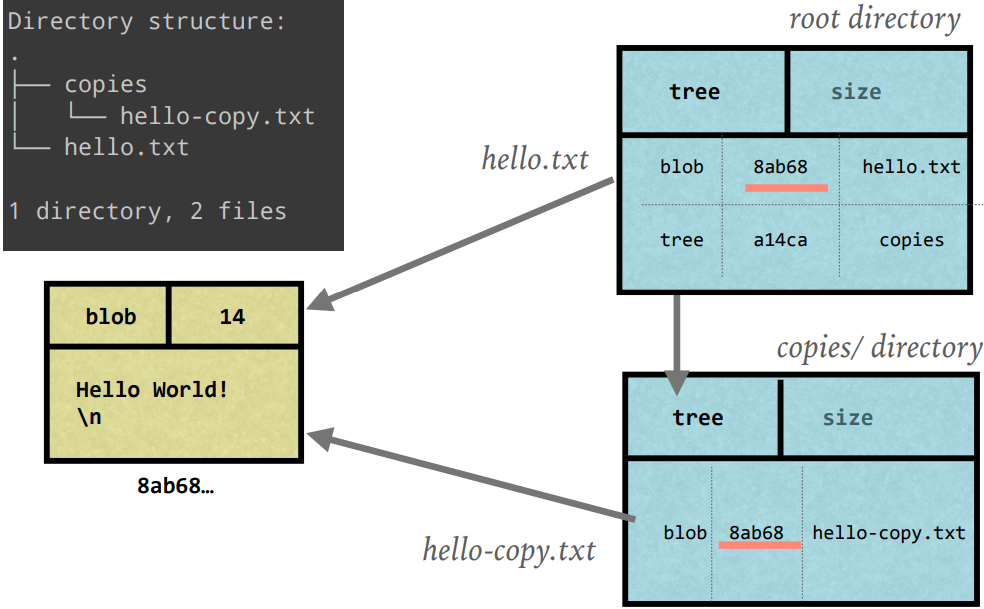
Identical content is stored only once
Other optimizations — Packfiles and deltas
- Git objects are compressed
- As files change, their contents remain mostly similar.
- Git optimizes for this by compressing these files together, into a Packfile
- The Packfile stores the object, and “deltas”, or the differences between one version of the file and the next.
- Packfiles are generated when, you have too many objects, during gc (
git commit), or during a push to a remote
Commits
Commit object
commit points to a tree
and contains metadata:
- author and committer
- date
- message
- parent commit (one or more)
the SHA1 of the commit is the hash of all this information

Commit structure

Commits points to parent commits and trees
A commit is a code snapshot
Commits under the hood — make a commit
Commits under the hood — look in .git objects
Commits under the hood — looking at objects
Oops, remember that content is compressed.
Git cat-file -t (type) and -p (print the contents)
Why we can’t change commits?
- If you change any data about the commit, the commit will have a new SHA1 hash
- Even if the files don’t change, the created date will
References — pointers to commit
- Tags
- Branches
- HEAD — pointer to the current commit

References to commit
References under the hood
refs/heads are where branches live
we show only part of the tree command output in the example
/refs/heads/master contains which commit the branch points to
HEAD is usually a pointer to the current branch
Share with your friends and followers
Start blogging about your favorite technologies, reach more readers and earn rewards!
Join other developers and claim your FAUN account now!

Danylo Halaiko
Student
@d9nich




User Popularity
98
Influence
10k
Total Hits
2
Posts

Read, Learn, Know, Teach
Hand curated newsletters for Developers, private Slack with like minded people, podcasts, job offers, news and more!

Only registered users can post comments. Please, login or signup.