







Part 1
An overview and design
Nowadays many things should be launched at a specific time, the first implementation which well-known is Cron with its crontab(for repeatable tasks) and at (for one-time tasks).
What if you have one, ten, or similar independent tasks? I suppose it’s OK, but when the number of tasks increased up to hundreds or even thousands, it becomes a headache. How to track tasks, how to control tasks, their exit conditions, and build conditional tasks?
For these, there is Airflow. Not only Apache Airflow, but we will consider Airflow[1].
Initially, Airflow was developed and released at Airbnb for inner necessaries. Now it is an open-source product.
Typical airflow instance has three components:
- airflow worker
- airflow scheduler
- airflow webserver
For storing results and metadata it is used database, we will consider Postgres, but also it may be MySQL, MSSQL, etc
For queues, airflow uses celery with Redis or RabbitMQ. We will use RabbitMQ with celery(since in our case Airflow works with CeleryExecutor).
A webserver, I think it’s clear the purpose of this. All airflow processes use a database.

pic 1. Airflow architecture
All these components can work on one or on different machines and communicate over a network. And then only one question arises: How to ensure uninterrupted and smooth work of the system?
If one of the airflow processes went down, then your tasks also will fail. It’s not what you expected and sometimes it might impact your business.
Now we came to the situation when it’s necessary to have an HA cluster. Also, there is a situation we came across, we want to run processes in different data centers if a provider does or does not support this option.
Fortunately, airflow since version 2, supports high availability out from a box. But this solution relies on a database, therefore not any RDBMS is suitable. More or less modern databases are good for this purpose. Airflow uses a lock mechanism in the database, it’s like mutex in multi-threaded programming. If we ran dag in one server, it cannot be started somewhere else until the database has a record regarding this task. All requirements you can find on the official website. In this tutorial, we are going to consider the PostgreSQL 13 version(the latest).
All applications considered below with specific versions will work together and they tested. Lower versions don’t guarantee to be worked. I tried to cover all questions anyone can come across during creating an HA cluster.
High Available Architecture
There are many articles and implementations of the Airflow cluster. But we are going to consider three-node cluster located in different data centers. Each node contains Airflow components, PostgreSQL, RabbitMQ, Celery. Only three of them should be working in cluster mode(synchronize its data over nodes)
Let’s see picture 2.

Pic 2. Airflow HA cluster design
Since a node consists of many components, it should use an encrypted connection. Configuring, issuing keys and certs for each component on each node is a bit tiring process. I recommend enabling VPN between nodes, let’s say Wireguard. It allows up secure connection only once.
PostgreSQL
a. PostgreSQL multi-master
As Airflow supports HA solution out of the box, it begs a native solution. We install airflow on three nodes and then install and configure PostgreSQL to run in multi-master mode. I won’t do a review of available solutions. I’ll only headline one thing, which didn’t mention in the official documentation. I came across this feature when I installed Bucardo[2] for multi-master replication:
https://github.com/apache/airflow/issues/15471#issuecomment-825107547
https://github.com/bucardo/bucardo/issues/231#issuecomment-894837272
Many solutions for replication trigger on
statements and doesn’t support
mechanism.
So it’s not suitable for us and I decided to find something else.
Have been reading docs for hours and comparing many solutions, I stopped on patroni.
Patroni is a solution for building HA PostgreSQL cluster written in python and uses distributed systems like etcd, zookeeper, or Consul.
b.PostgreSQL master-slave with Patroni
Let’s have a look at pic.3
Now we have a PostgreSQL cluster with only one master and a few slaves. How does the system decide where to send queries? Let me introduce Patroni.
Patroni uses etcd for electing master, or rather not electing, just for setting master based on info from etcd. All work by electing master does etcd(in our case). The idea is that Patroni launches an HTTP server that returns 200 for master and 503 for slaves. This is used by load-balancer for checking the health and forward traffic to healthy instance(master):
http://master/master returns 200(OK)
http://slave/master returns 503(Service unavailable)
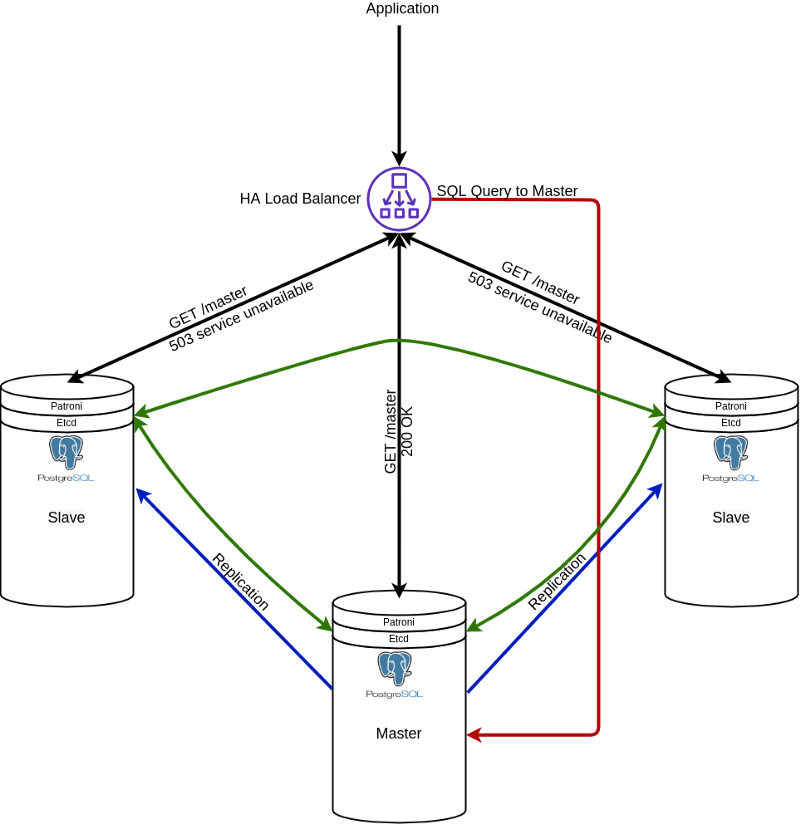
Pic 3. Master-slave Postgresql cluster with patroni
Alright, PostgreSQL cluster design has been done.
High available Celery
Actually, there is no HA for celery, celery works on each node independently and communicates with a message broker which is highly available. For Celery monitoring, there is application ‘Flower’.
HA message broker
Airflow supports two brokers: Redis and RabbitMQ.
As we are going to build an HA cluster, it requires a broker should be high available too or distributed over cluster nodes.
Initially, I decided to use Redis, because I am familiar with it. Then I found a utility from Netflix called Dynomite[3]. It looked nice to be used in my cluster. The description told it allows to build multi-master clusters. And I started to use it.
When everything was done I realized it didn’t work, because Redis had implemented new features in protocol. I had to give up using Netflix’s application.
RabbitMQ cluster
RabbitMQ supports high availability by default, also it has a web server to control the RabbitMQ cluster, you can see its status, stop, start and perform other actions on instances. For security reasons, it is not recommended to open access from the Internet.
DAGs synchronization
If you have a possibility to connect a shared volume to each of the three nodes, the further paragraph you can skip.
As we have a few nodes and each node has its own web server when a user is creating a new task, this new just created DAG will be saved on the same machine where this webserver works. Therefore it’s necessary to synchronize DAGs among all nodes in a cluster since workers can be switched over nodes or worked in parallel. For this role, I recommend using csync2[4] and crontab. From my side, I can explain why I have chosen csync2 + crontab. Initially, I saw the bundle lsync [5] + csync2 as an ideal. Let’s see, lsync can track changes on filesystem using inotify syscall, and then csync can synchronize these modified files.
There are many tools that allow syncing files between machines, but csync2 has an advantage — it can work in clusters with nodes more than two. Looks fine, doesn’t it? Further, while I was testing the solution, I found it was a bad idea.
lsyncd fails if csync2 cannot connect to a remote server, for instance, if one node is down. In this case, csync2 returns 1 and lsync fails. I didn’t manage to change this behavior. That’s why I decided to use crontab to run csync2 every minute instead of lsync.
If someone knows a better solution, please let me know.
So this is the end of part 1. See you in part 2, where we will consider the implementation and installation process step by step.
Sources:
[1] https://github.com/apache/airflow/
[2] https://github.com/bucardo/bucardo/
[3] https://github.com/Netflix/dynomite
Share with your friends and followers
Start blogging about your favorite technologies, reach more readers and earn rewards!
Join other developers and claim your FAUN account now!

Denis Matveev
sysadmin/devops, Ignitia AB
@denismatveev


User Popularity
77
Influence
8k
Total Hits
3
Posts
Mentioned tools


Read, Learn, Know, Teach
Hand curated newsletters for Developers, private Slack with like minded people, podcasts, job offers, news and more!

Only registered users can post comments. Please, login or signup.