






We will do every major tasks and to do’s which is required in Web Scraping! So don’t worry and Just Read on! :) You are going to learn a lot! I have provided all the resources and link. This will be a three series article for the sake of simplicity. :)
We will do every major tasks and to do’s which is required in Web Scraping! So don’t worry and Just Read on! :) You are going to learn a lot! I have provided all the resources and link. This will be a three series article for the sake of simplicity. :)

Photo by Kevin Ku on Unsplash (source)
Guide:
1. Installing Libraries through pip install in your command line.
2. Requesting and Beautifying HTML data over the internet from your Python Script.
3. Grabbing elements off of so called ‘Soup’
NOTE: You should take prior permission before scraping any website, many of them block such script requests. Some websites may block your IP Address if you make too many requests.
We will use Scraping friendly websites which allows these requests without any side effects.
This is Part 1 and We will be installing only libraries here!
Install packages by running these commands one by one or you can just copy paste them in one go:
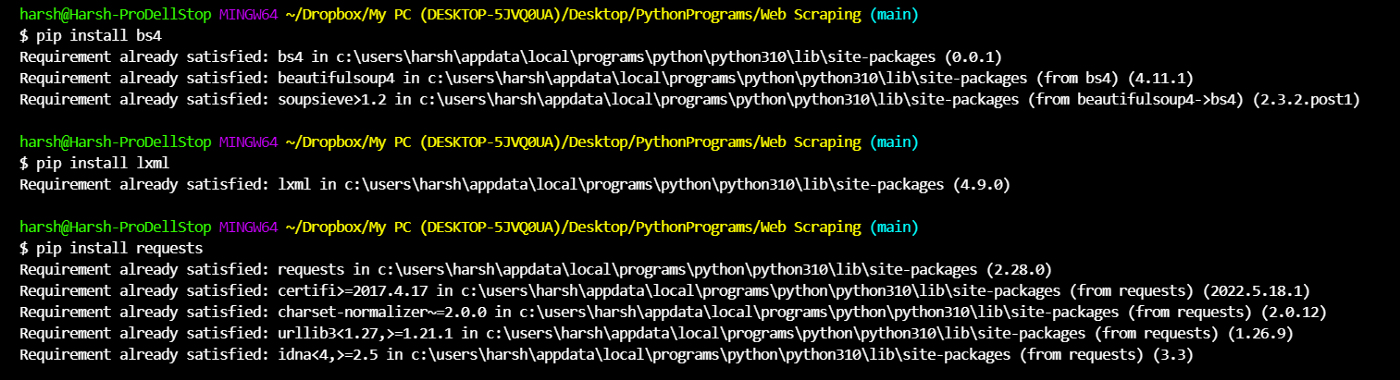
I have already installed
My output shows requirement satisfied as I have already installed/downloaded it!
bs4
Beautiful Soup is a Python library for pulling data out of HTML and XML files. It works with your favorite parser to provide idiomatic ways of navigating, searching, and modifying the parse tree. It commonly saves programmers hours or days of work.
Check this command and ensure if your firewall is letting you to make this request.

bs4 documentation page
Source: https://www.crummy.com/software/BeautifulSoup/bs4/doc/
lxml
lxml is the most feature-rich and easy-to-use library for processing XML and HTML in the Python language.
The lxml XML toolkit is a Pythonic binding for the C libraries libxml2 and libxslt. It is unique in that it combines the speed and XML feature completeness of these libraries with the simplicity of a native Python API, mostly compatible but superior to the well-known ElementTree API. The latest release works with all CPython versions from 2.7 to 3.9.

Looks kinda funny…
Source: https://lxml.de/
requests
Requests allows you to send HTTP/1.1 requests extremely easily. There’s no need to manually add query strings to your URLs, or to form-encode your PUT & POST data — but nowadays, just use the json method!
Requests is one of the most downloaded Python packages today, pulling in around 30M downloads / week— according to GitHub, Requests is currently depended upon by 1,000,000+ repositories. You may certainly put your trust in this code.
requests landing page
Well Done! This finishes our task 1! You have now installed and learnt about all the packages we will need to successfully perform web scraping! :)
Checkout my GitHub repository for Web Scraping, All the files are included:
GitHub - developergaurav-exe/web-scraping-in-python: Web Scraping in Python through BeautifulSoup…
Hop on to next article to learn about:
Requesting and Beautifying HTML data from a site through your Python Code.
How to do Web Scraping in Python? | Part 2
~Follow Harsh Gaurav for more Technical and Interestingly random content :)
Share with your friends and followers
Start blogging about your favorite technologies, reach more readers and earn rewards!
Join other developers and claim your FAUN account now!

Harsh Gaurav
@developergaurav-exe


User Popularity
28
Influence
3k
Total Hits
3
Posts

Read, Learn, Know, Teach
Hand curated newsletters for Developers, private Slack with like minded people, podcasts, job offers, news and more!

Only registered users can post comments. Please, login or signup.