






We will create a real-time facial emotions recognition system using python. This system can be tested on both videos including webcam and photos.
In this project, we will create a real-time facial emotions recognition system using python. This system can be tested on both videos including webcam and photos.
Here’s a demo video of the project before we dive into the code:
Dataset
FER2013 dataset was used for this project. FER2013 is an open-source facial emotions recognition dataset containing approximately 30,000 grayscale, resized images 48×48 pixel images. The goal is to put each face into one of seven categories (0=Angry, 1=Disgust, 2=Fear, 3=Happy, 4=Sad, 5=Surprise, 6=Neutral) depending on the emotion expressed in the facial expression. There are 28,709 instances in the training set and 3,589 examples in the public test set.
Import Libraries and Dependencies
Tensorflow library was used for training the machine learning model along with Keras for developing a neural network architecture.
Loading the dataset
For this project, the training was performed in Google Colab. Hence the training and testing dataset were unzipped in the colab.
Mounting Google Drive:
Installing unrar so that it can be used to retrieve data. Note that you need to keep the zipped folders of dataset in your drive
Exploring Dataset




Preparing Dataset for Training
Model Architecture




Model Training

Evaluating Model Performance
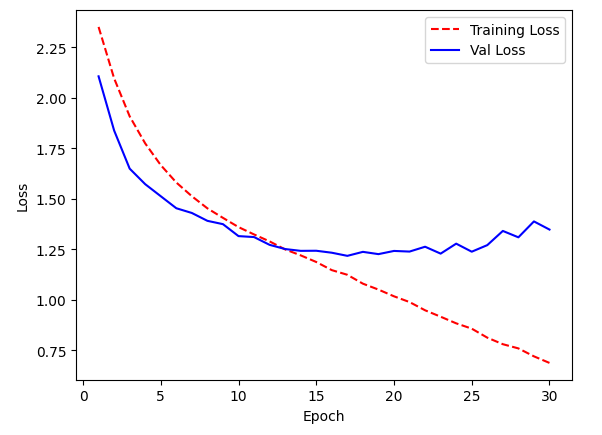
PLOTTING TRAINING LOSS/ VAL-LOSS VS EPOCHS
PLOTTING ACCURACY/VAL_ACCURACY VS EPOCHS

Saving Model
Saving the trained model is important so that it can be loaded later for testing without the need of training all over again
Test dataset accuracy
Plotting predictions

Real time Testing (Webcam/Videos)
Testing part is executed on Jupyter Notebook and not on Google Colab. Make sure to provide the path for trained model which we saved after the training. Drawing a rectangle over the face is an optional part. To run that part make sure you provide the path of frontal face haarcascade xml file
Share with your friends and followers
Start blogging about your favorite technologies, reach more readers and earn rewards!
Join other developers and claim your FAUN account now!








User Popularity
79
Influence
8k
Total Hits
3
Posts

Read, Learn, Know, Teach
Hand curated newsletters for Developers, private Slack with like minded people, podcasts, job offers, news and more!

Only registered users can post comments. Please, login or signup.