Join us
@fizza-rubab ・ Oct 04,2022 ・ 13 min read・ 998 views








An Introduction to Cloud COPASI
Cloud-COPASI is a web-based service for running computationally intensive simulation and analysis tasks in parallel on a high-throughput computing pool. Cloud-COPASI can connect to existing computing pools, or provides a simple interface for launching a new computing pool using the Amazon Elastic Compute Cloud (EC2).
Cloud-COPASI can run several simulation and analysis tasks, including global sensitivity analyses, stochastic simulations, parameter scans, optimizations, and parameter fitting. Each task is submitted to the server and automatically split into several smaller jobs, which are executed in parallel, allowing for significant speed-ups in running time.
How it Works
The flow of the web application is simple. The user registers on the website and logs in to his dashboard. He has two options for adding a pool to his account:
Once the pool is added, the user can upload a locally created COPASI model file and its data and select the relevant simulation task and submit it to the pool. The pool performs simulation and returns results much faster than the stand-alone COPASI desktop application.
Problem
The current implementation of Cloud-COPASI requires a user to first configure SSH access to the submit node using a public/private key pair. This assumes that for a user to be able to use Cloud-COPASI they must have login access (user account) to such a pool. This is undesirable as most of the users of Cloud COPASI are not tech savvy and refrain from using the application because of the complicated SSH configuration. This involved process is a hindrance to research and analysis.


The user flow to add a pool in the normal cloud COPASI version
Goal
The goal of this project was to create a customized version of Cloud-COPASI that already has a predefined HPC pool connection which will be used by all registered users of this version of Cloud-COPASI. This will remove the need for the complex SSH configuration process and will allow users to have a ready-made pool connection after they register.
Moreover, researchers at the University of Connecticut wanted to provide simulation services on our own HPC center to users that may otherwise not have access to HPC facilities.
The special cloud COPASI version would have a very simple flow and would allow users to submit job immediately with the pre-defined pool.
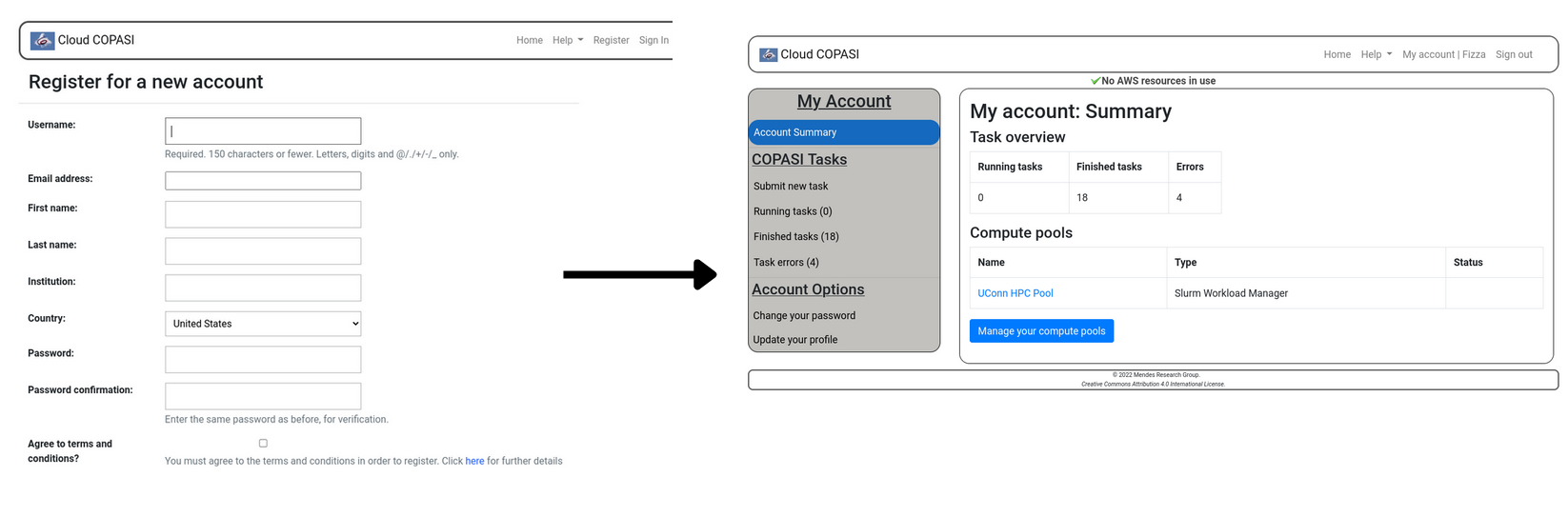
UConn HPC Pool gets added to user’s account on registration in Special Version of Cloud COPASI
Mentors
My mentors for this project were:
Project Timeline and Milestones
In this community bonding period, I interacted with both of my mentor and co-mentor, understood the purpose and flow of the application. I mainly focused on understanding code and devising a milestone plan.
I started working early on the project before the coding period even started. I first modified the settings.py file and added a variable that could toggle between the special and general versions of Cloud COPASI. I added a few other variables necessary for the predefined connections. I altered some of the templates and views to remove the unnecessary AWS functionality which was not desired in the special version.
During this period, I worked on creating a predefined connection to UConn’s HPC on user registration. This was done by modification of the account registration view. A service COPASI (svc_copasi) account was created that would now submit jobs to the submit node instead of the individual user accounts. Since the service account had some issues with incorrect partition, I tested my progress on my own account on the submit node and it worked just fine.
This period involved intensive debugging and fixing the svc_copasi account problems. Once those were fixed, the server with the special cloud COPASI version was ready. I tested it on all model files and after some debugging achieved satisfactory results. I stress-tested the system by submitting all different tasks simultaneously and each of them got processed efficiently and correctly.
What did I do in the rest of my GSoC period? Jump to Going Beyond section and find out!
Approach Overview
In the standard settings.py file of the Django server, I created a variable SERVER_VERSION that would serve as a toggle between the two versions of cloud-COPASI. This ensured that there was an easy transition between the two versions. With the help of my mentors and the UConn HPC facility a service account user svc_copasi was created in the HPC that would submit all jobs from all of the users now instead of relying on their individual accounts. A few other setting variables were hard-coded for the HPC submit node which included the address of the node, the service user, the QoS and partition specification for jobs, and the private ssh key path of the svc_copasi user on the web-server which would be accessed authenticate to authenticate him against the submit node and submit jobs.
Once the settings were modified, I had to remove unnecessary AWS functionality from the rendered templates. I accomplished that by adding a keyword argument ssh_free in all parent views (DefaultView, RestrictedView and RestrictedFormView) that were used for creating pool, account and task views.
Then, in the relevant HTML pages that rendered AWS content, I simply added if conditions using Jinja templating, to only render the AWS pools and keys content if the server configuration is general i.e, ssh_free==False. The templates were modified in the following manner:
This visual output looked like this:

Once the views and templates were adjusted, I had to devise the logic to add the UConn HPC Pool for every user that registers. In the form_valid function of AccountRegisterView class, after the user gets registered the function does some extra tasks. It adds the default UConn HPC Pool for the user. Following steps take place.
bosco_cluster — add command and the parameters are retrieved from the submit node settings defined earlier.On execution of all of these steps, the newly created user gets redirected to his dashboard where the UConn HPC Pool has been added and they can submit jobs without further ado.
This was essentially my approach which after a lot of debugging, testing and revising worked out nicely!
My Key Contributions
For this GSoC task, I was assigned a separate development server to work on: http://cloud-copasi.cam.uchc.edu . It is up and running and currently has multiple users spread across different countries using it for simulation purposes.
I used SSH to log in to this machine and began my work by creating a new branch dev from master .
Following is my commit history and descriptions for each commit.
In my first commit, I attempted to tackle the problem, by creating a SSH free version on user level instead of considering it as a server configuration. I added a enable_ssh_free_version check field in the AccountProfileForm and added it into the Profile model in models.py as well. Passing it as a keyword argument from the views to the templates, I was able to modify and remove AWS content from HTML pages using conditions as mentioned earlier in the approach.
I realized the issue in my earlier approach and discussed the need for a SSH-Free Cloud Copasi version on the server level. In this commit, I modified the settings.py file to contain details of the submit node and the version server is running on. I removed the enable_ssh_free field from Profile model and made migrations. Furthermore, I coded the addition of a predefined pool in AccountRegisterView and tested it on my local account instead of the svc_copasi one because of some misconfigurations in the service account. I modified all HTML templates to remove AWS content from account/ and pool/ sub-folders. task_views.py file was also modified to add log statements for debugging.
HTML Templates that attempted to generate, share or delete AWS keys were disabled by using conditions based on the ssh_free variable passed as a keyword argument to the template.
This commit fixed a few bugs. Around this time, the svc_copasi account was running and tested thoroughly. This commit involved renaming of the pool to ‘UConn HPC Pool’ as well as editing a few other templates that had AWS remnants left.
This commit merged remote-tracking branch ‘origin/master’ into dev because a new task/model type, ‘Profile Likelihood’ had been added to cloud COPASI.
This commit merged branch ‘master’ into dev because requirements.txt file had been updated with Django version 4.0.6.
For users running the special version of cloud COPASI, the deleting the automatically UConn HPC Pool should not be an option. This commit removed the delete button for the default pool.
As I am still working on the cloud COPASI even after the GSoC period ends, I plan to refine code further by cleaning and refactoring it and removing extra log statements that I might have added.
Going Beyond
Since I finished my main GSoC task before anticipated time, my mentors decided to put me on improving Cloud-COPASI further by upgrading its another feature of letting users run their simulations on AWS cloud computing pools. Cloud COPASI has an AWS(Amazon Web Services) module that allows users who do not have access to an HPC Pool, to launch their own AWS EC2(Elastic Compute Cloud) pool through the simple interface. The only prerequisite for this is to have an AWS account.
This part of the code was written in boto which is a python SDK/API for AWS. However, boto is now obsolete and the code written in python2 is dead and non-functional.
I was assigned the task to revive the code and migrate the code-base to boto3 which is the recommended latest AWS API library for python3.
Initially, I spent two weeks understanding the existing AWS dead code, learning the basics of AWS and EC2 instances, and exploring Boto3. Since then, there has been significant progress in the AWS pool instantiation. I am currently working in aws branch in the repository. Following are the updates:
KeysAddView form where they need to provide the Access Key ID, Secret Access Key and the region of their key.UserData is different for master and worker through which IPs are configured accordingly.Boto3 requirement added to requirements.txt fileKeysAddViewcode updated to boto3 . Now users’ can add a key-pair and the VPC gets created in their AWS account.boto3.key_shareN.htmlboto3 requires region to be specified. This has been added into AddKeyForm and in the model as well.ec2_tools.py migrated to boto3So far everything works nicely. The pool gets initialized and appears on the dashboard. However, when the pool is tested with the model file or submitted a task, it fails. The files are transferred to the submit node as the logs indicate, however processing gets halted. The debugging is under process. Once this gets accomplished, the only milestone left will be testing and error handling!
Challenges Faced
My GSoC journey had ups and downs. I faced a few challenges in debugging errors that arose due to wrong server and account settings (for example incorrect partition), Condor and Bosco related issues, etc. but I was able to navigate through them with the help of my mentors. It took me time to get accustomed to writing code on a server to whom I only had SSH access, unlike my familiar VSCode environment. The AWS revival feature that I am currently working on, is very challenging and thus all the more fun! What fun is there when there is no challenge?
Future Improvements
There are several aspects in which Cloud-COPASI can be improved.
Final Thoughts
GSoC 2022 was a wonderful and exciting journey for me. It was my stepping stone in the arena of open source development and I learned a lot. There have been ups and downs, consecutive weeks where I couldn’t make significant progress but then days where I finished my tasks earlier than expected. Persistence is the key and so is communication with the mentors and organizations.
A Token of Thanks
I am extremely grateful for my mentors and their constant guidance and support. They are an inspiration and I hope that I get to continue interacting with them in the future!
I am grateful for my professors for their encouragement and I would also like to thank my family and friends who uplifted me in difficult times and supported me through thick and thin!
Contact and Connect
Feel free to connect with me on the following platforms!
Share with your friends and followers
Join other developers and claim your FAUN account now!
Influence
Total Hits
Posts

Hand curated newsletters for Developers, private Slack with like minded people, podcasts, job offers, news and more!


