Join us
@iusztinpaul ・ Aug 08,2022 ・ 4 min read・ 1k views








As machine learning engineers or data scientists, we all got to the point where we built our beautiful models with wonderful test results to end up using them just in a PowerPoint presentation. The most standard way of interacting with a model is to use it in an offline setup, where we have some kind of dataset to play with. This is ok for experimentation and to build your initial model. But, the next step would be to put our precious model out in the wild so people can use it. This is what model serving is all about. It represents the mechanism of deploying the model so other people can interact with it.
As machine learning engineers or data scientists, we all got to the point where we built our beautiful models with wonderful test results to end up using them just in a PowerPoint presentation. The most standard way of interacting with a model is to use it in an offline setup, where we have some kind of dataset to play with. This is ok for experimentation and to build your initial model. But, the next step would be to put our precious model out in the wild so people can use it. This is what model serving is all about. It represents the mechanism of deploying the model so other people can interact with it. With model serving, you can move from experimentation to production.
The most common ways of serving a model are:
⚙️ In a Model-as-Dependency setup, the model will be used directly by the application. For example, in a Python project, it will be installed as a package through pip or integrated into your code directly from a git repository. I think this is the easiest way, conceptually, to serve a model, but it comes with some downsides. Where the application runs, you need to have the necessary hardware for your model, which sometimes is not possible. Also, the client of the model will always have to go through the pain of managing the dependencies of the model, which in some cases is a real pain.
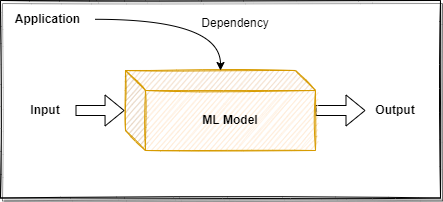
Model-as-Dependency
⚙️ In a Model-as-Service setup the model will be accessed through a web API (e.g. RESTful API). In this way, the client can treat the model as a black box. It only has to know the model's inputs and outputs. The rest of the article will explain in more detail how the Model-as-Service works.

Model-as-Service
Model-as-Service
As we said the Model-as-Service will be used by its clients through a web API. Maybe for some of you, it sounds scary, but the core concepts are simple. Its architecture will have the following components:
1️⃣ The actual model is the result of our experiments which is usually saved into different formats relative to the framework we have used (e.g. Scikit, Pytorch, Tensorflow, Keras, etc.). The best practice is to save the model into a registry that supports some sort of versioning. Therefore, we have control over our model evolution and we can easily download it from anywhere. Also, when we want to upgrade our model from production, we will just have to change the model version from the configuration and we are good to go (we can easily version our model with tools like ClearML).
2️⃣ Almost any model needs the inputs into a specific format and some sort of interpretation of the predictions. That is why, for every specific problem, we will need to write custom code for preprocessing our model inputs and postprocessing the predictions (e.g. here we will write Python or C++ code that interprets your data).
3️⃣ To be able to access our model through a web API we will need to write a web layer over our model and custom code. Usually, this can easily be done, in Python, with frameworks like Flask or FastAPI. We will build a web server that can be accessed on the internet through a set of endpoints, like any other backend application. As a remark, we should use Flask or FastAPI if we intend to build a RESTful API, but we can easily change this to other types of communications. For example, if we want to stream the predictions of the model, we can use the same concept, but just change the Flask/FastAPI layer with Kafka (or another streaming tool).
4️⃣ To isolate your application and its dependencies we will have to containerize it. The most common way to do this is with Docker.
5️⃣ To be able to scale our API requests we will need a way to orchestrate our Docker containers. This can be done with Kubernetes or other similar tools.
As you can see, we are using technologies that we already know or at least we are familiar with. With this technique, we can easily deploy our models by just using already existing tools.
Now we will have on-demand predictions that can be accessed easily from different clients like mobile, browsers, microservices, etc.

Model-as-Service Infrastructure
If we managed to containerize our model we can use different cloud vendors that can easily host our application. Amazon AWS Sagemaker, Google Cloud AI Platform, Azure Machine Learning Studio, and IBM Watson Machine Learning are the most common examples.
Also, we can build a similar system, on-premise, with tools that give us serving possibilities: ClearML, TorchServe, etc.
Conclusion
As we saw, with model serving we can move from experimentation to production. For business porpoises this step is crucial, otherwise, our model cannot give value by being used by other people. Also, we saw that the main concepts of model serving are easy to understand and perform.
Thank you for reading my article!
Do not hesitate to reach me via the following :
Share with your friends and followers
Join other developers and claim your FAUN account now!

Machine Learning Consultant
@iusztinpaul

Influence
Total Hits
Posts

Hand curated newsletters for Developers, private Slack with like minded people, podcasts, job offers, news and more!
