







Learn How to read the parquet file in data frame from AWS S3
Today we are going to learn How to read the parquet file in data frame from AWS S3 First of all, you have to login into your AWS account. After successfully login, you have to check your parquet file, is it available at s3 Bucket.
In the beginning you have to import the following:
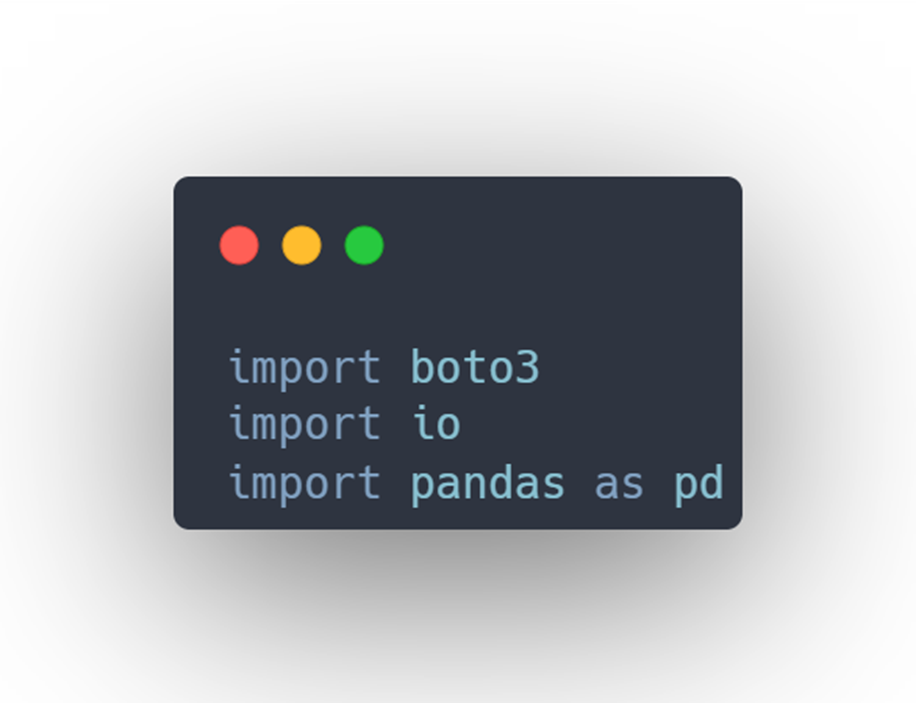
Let me explain little bit about the above.
Boto3
Boto3 is the Amazon Web Services (AWS) Software Development Kit (SDK) for Python, which allows Python developers to write software that makes use of services like Amazon S3 and Amazon EC2.
Io
Python io module allows us to manage the file-related input and output operations. The advantage of using the IO module is that the classes and functions available allows us to extend the functionality to enable writing to the Unicode data.
Pandas
pandas (all lowercase) are a popular Python-based data analysis toolkit which can be imported using import pandas as pd. It presents a diverse range of utilities, ranging from parsing multiple file formats to converting an entire data table into a NumPy matrix array. This makes pandas a trusted ally in data science and machine learning.
Just like what we do with variables, data can be kept as bytes in an in-memory buffer when we use the io module’s Byte IO operations. BytesIO creates an in-memory buffer, optionally filled with the string you provide as argument, and lets you do file-like operations on it.
So, our next code line is:

to access the AWS s3 resource, type the access key id and secure key:

put the Bucket name and file name by using following code:

download_fileobj() download an object from S3 to a file-like object. The file-like object must be in binary mode.
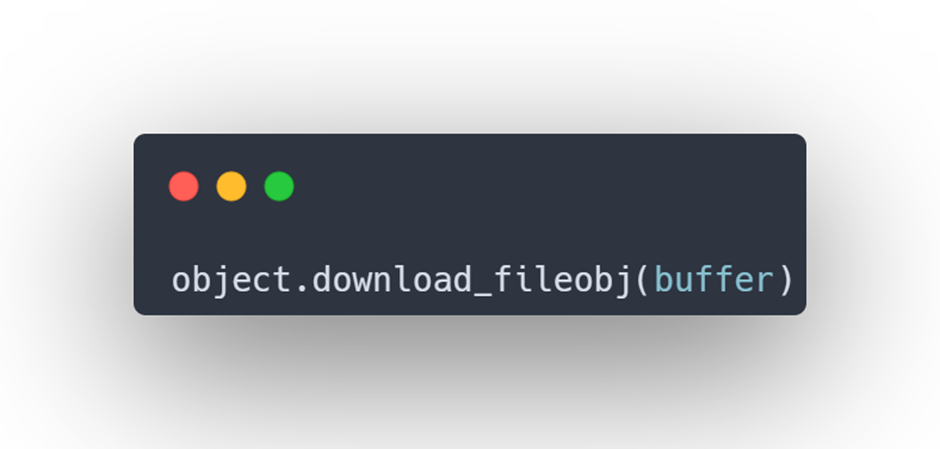
read the buffer

print the df:

After this you will be able to see your data in terminal windows.
Complete code:

Share with your friends and followers
Start blogging about your favorite technologies, reach more readers and earn rewards!
Join other developers and claim your FAUN account now!
Mudassar Hussain
Senior BI Consultant, Apptech Technologies
@mudassarlhr
User Popularity
230
Influence
23k
Total Hits
1
Posts

Read, Learn, Know, Teach
Hand curated newsletters for Developers, private Slack with like minded people, podcasts, job offers, news and more!

Only registered users can post comments. Please, login or signup.