







Tradeoffs are hard. Think about the time when you had to choose between two equally compelling options - (a) addressing technical debt or (b) pushing out that long-awaited feature release, and risk breaking production. Or when your team couldn’t agree on where to draw the line on improving request latency versus shipping a major new update.
If this sounds familiar, count yourself as part of the Eternal Conundrum Club of Reliability Engineering. It’s fairly easy for us as humans to communicate the impact of a new feature release as opposed to the utility of cleaning up a part of the system that would cause us to worry less. This is because feature releases are more often than not, tied with business impact, ie. potential to generate revenue, but it’s a little harder to quantify and justify the business impact resulting from engineering reliability into your offering.
Alas, without a healthy balance between release velocity and reliability engineering, you’re going to end up with not only unhappy customers but also unhappy teams. Often, teams realize this problem too late - when business outcomes have already taken a hit.
Hello Error Budgets!
The key to resolving this dilemma is to add more context. This can support your decision making by helping you understand the tradeoffs between release velocity and reliability engineering. Error budgets are one such example of a quantifiable measure that can aid this decision making in real-time. Once we accept that risk cannot be avoided, but can be managed, it becomes easier to understand the utility and application of error budgets.
Error budgets tie back to the concept of SLIs, SLOs, and SLAs. Here’s a quick outline of what they mean -
Service Level Agreement (SLA) is a promise between you and your customers on the acceptable availability of your system over a certain time period and it outlines business implications and compensation in the event of a breach. Essentially, not maintaining your SLA is going to hurt your bottom line.
Service Level Objectives (SLOs) are just another variation of SLAs which are owned internally by the product and engineering teams. SLOs are typically stricter than SLAs to ensure that an SLO breach precedes an SLA breach. Every customer-impacting service must have an SLO which will serve as its quantitative reliability measure. This is defined in alignment with business stakeholders as it is imperative for them to be on top of the SLAs they can promise to customers. They also need to quantify and explain to their engineering team about the cost attached to downtime and its adverse effects on the business reputation.
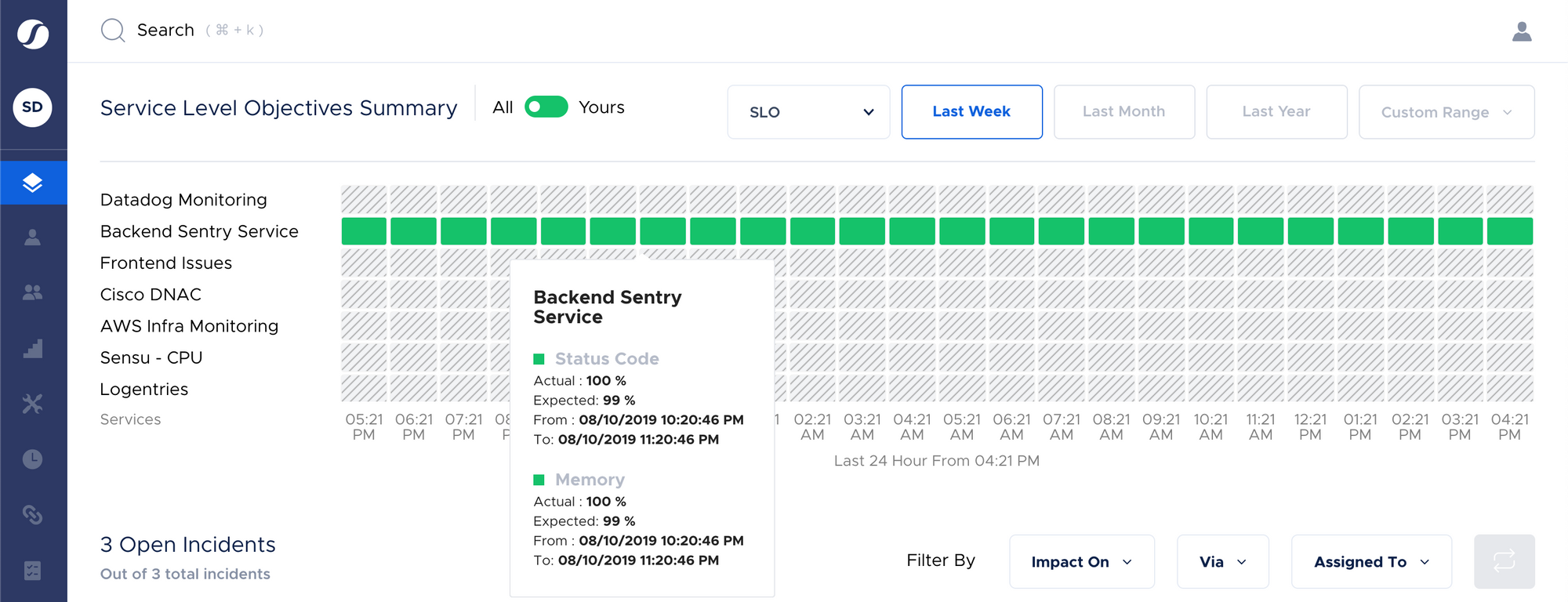
Service Level Indicators(SLIs) are metrics that can be monitored and can act as quantifiable indicators of the quality of the service you provide to your customers.They are a direct measurement of a service’s behavior and are typically documented in service level agreements (SLAs), as well as in service level objectives(SLOs).

This is where Error Budgets come in.
Typically availability is calculated as:
Availability = Uptime / (Uptime + Downtime)
Let’s say a failed request covers errors, no responses and slow responses (eg. if it’s too slow for a customer and they move on to something else) which are direct indicators of the customer experience.Now, the Error Budget for a service can be calculated as:
Error Budget = (1 - Availability) = Failed Requests / (Total Number of Requests)
So if an SLO for a service is indicated as an Availability of 99.5%, then this service has an error budget of 0.5% which specifies the amount of total downtime you are allowed.
Settling the debate
Error Budgets are the single metric that can be utilized to determine whether the system can take on the additional risk of deploying a new feature or if the team should rather be focussed on making the system more reliable. If the error budget is close to being spent, then the product team should ideally be extra cautious about deploying new features. It is liberating to have error budgets as a key decision making metric to solve this conundrum in any organization, no matter the size.
You could start by keeping a close watch on the error budget consumption for all the dependant services of a new feature release. The decision to balance release velocity with reliability engineering tasks then becomes a more objective one. When the error budgets are nearly consumed, the team should collectively agree to focus on improving the reliability of the current system.
Squadcast is an incident management tool that’s purpose-built for SRE. Create a blameless culture by reducing the need for physical war rooms, centralize SLO Tools dashboards, unify internal and external SLIs and automate incident resolution with Squadcast Actions and create a knowledge base to effectively handle incidents.
Share with your friends and followers
Start blogging about your favorite technologies, reach more readers and earn rewards!
Join other developers and claim your FAUN account now!
Squadcast Inc
@squadcast





User Popularity
4k
Influence
364k
Total Hits
447
Posts

Read, Learn, Know, Teach
Hand curated newsletters for Developers, private Slack with like minded people, podcasts, job offers, news and more!

Only registered users can post comments. Please, login or signup.