







It’s been almost two years since we released KYPO cyber range platform¹ as Open-source project. KYPO consists of 10 microservices and up to 8 supporting services making deployment and configuration a complex task. We’ve released two projects to make it simpler:
kypo-crp-openstack-base² — set of shell scripts and heat templates for OpenStack cloud resources allocation
kypo-crp-deployment³ —Ansible playbooks and roles for application provisioning
We soon realized that orchestration with Heat and shell scripts is not flexible enough, so we’ve replaced it internally with Terraform.
Legacy deployment
The final legacy deployment consists of the following steps:
- Deployment execution (GitLab CI) — responsible for setting up and executing step 2.
- Cloud resources orchestration (Terraform) — creates all OpenStack resources (VMs, virtual router, networks, subnets, floating IPs, security groups, key pairs) and executes steps 3, 4, and 5.
- Configuration management (Ansible) — installs all required packages, creates configuration files, and sets up Docker Compose templates.
- Execution of Docker Compose application (Ansible)
- Initial application data provisioning (Ansible) — LDAP users, DB accounts …

Legacy deployment
As you can see, we’ve successfully removed all manual tasks, but it wasn’t still all rainbows and unicorns. After several months in production, we’ve discovered these issues:
- It’s not easy to create HA and scalable setup just with Docker Compose.
- It’s not 100% Infrastructure as code. It might sound strange with fully automatized deployment, but it shouldn’t surprise anyone familiar with any configuration management tool (and yes, it’s Ansible’s fault). If you stop managing some resources (packages, files) with Ansible, they are left on your system, which can sometimes lead to non-functional configuration. If you want to redeploy a whole application, you need to remove everything and go through all five steps again (in our case, it takes 30 minutes under ideal conditions).
- Installation of packages from pip, but even from system package manager tends to break over time.
- It’s hard to tell what changes are introduced by the repeated execution of Ansible playbooks. Due to the imperative nature of Ansible playbook execution (remember that only single task execution is declarative, but all tasks are executed in strict order), Dry Run isn’t the most reliable source of information. This makes doing changes to the live system even more of an adrenaline experience than watching the movie Martyrs⁴.
- Ansible execution in Terraform generated a long code (shell script) that is insanely hard to modify without breaking anything.
Helm deployment
To tackle most of the issues, we’ve decided to migrate to Helm & Kubernetes. We’ve created the kypo-crp-helm⁵ project, a replacement for the kypo-crp-deployment project. Ansible roles were refactored into set of subcharts deployed by one common umbrella chart.
We had an issue with the old deployment that we needed to maintain the kypo-crp-openstack-base project for a community, but we’ve used internally Terraform code instead. To remove this dual work, we’ve created a set of Terraform modules⁶ that are used both by a new community deployment project⁷ and by our internal tools (removing redundant work).
The current deployment workflow consists of these steps:
Infrastructure deployment
- Deployment execution (GitLab CI) — responsible for setting up and executing step 2.
- Cloud resources orchestration (Terraform) — creates all OpenStack resources (VMs, virtual router, networks, subnets, floating IPs, security groups, key pairs) and Kubernetes cluster within OpenStack VMs.
Application deployment
- Deployment execution (GitLab CI) — responsible for setting up and executing step 2.
- Helm packages orchestration (Terraform) — deploys Helm packages to running Kubernetes cluster.
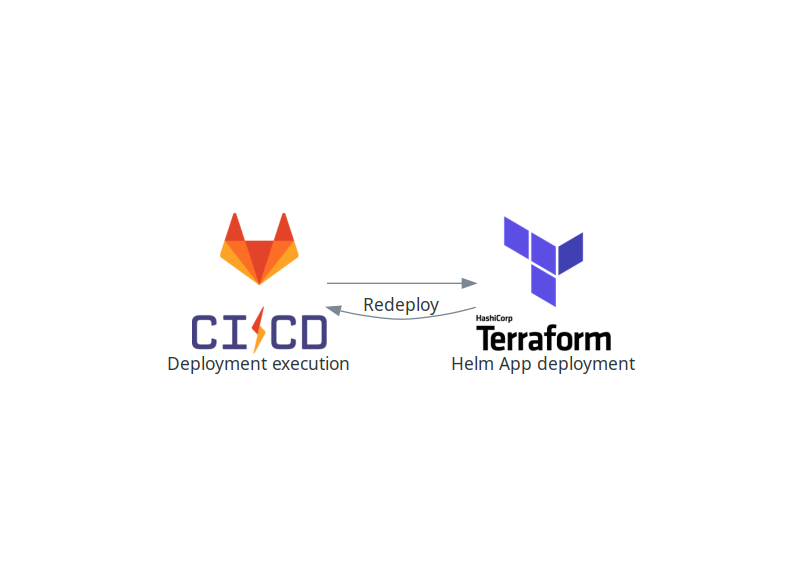
Helm deployment
Benefits of a new deployment model:
- With Kubernetes, it’s easy to scale applications and maintain HA
- It’s 100% Infrastructure as code. All application resources are managed by Kubernetes. If you remove a resource from configuration, it will be removed from Kubernetes when applying the Terraform code. We no longer need to recreate the whole VM when doing redeployment. We just need to reinstall Helm packages, which enabled the separation of Infrastructure and Application deployment. Redeployment of Helm packages currently takes several minutes (depending on the amount of new Docker images) compared to half an hour with legacy deployment.
- There is no package installation in the Application deployment stage. Only external dependency are a few Docker images making deployment stable over longer period of time.
- Due to the declarative nature of both Terraform and Helm/Kubernetes, all changes being introduced with updates are displayed before repeated execution of Terraform, making it relatively stress-free.
- Current Terraform code is simple and easy to maintain.
- Rollbacks baby.
Conclusion
Was all the effort worth it? The new deployment model brought almost only positives. Code is now easier to read and maintain, and operations are more reliable and deterministic. I was a bit worried about adoption among the rest of the team, but I was pleasantly surprised by my colleagues, who immediately started sending merge requests to both new and legacy deployments. And we had a lot of fun in the process. If this is not all rainbows and unicorns, I don’t know what is.
PS: If you want to play with KYPO CRP without significant effort, try our zero-configuration tool KYPO lite⁸.
[2] https://gitlab.ics.muni.cz/muni-kypo-crp/devops/kypo-crp-openstack-base
[3] https://gitlab.ics.muni.cz/muni-kypo-crp/devops/kypo-crp-deployment
[4] https://www.imdb.com/title/tt1029234/?ref_=nv_sr_srsg_0
[5] https://gitlab.ics.muni.cz/muni-kypo-crp/devops/kypo-crp-helm
[6] https://gitlab.ics.muni.cz/muni-kypo-crp/devops/terraform-modules
[7] https://gitlab.ics.muni.cz/muni-kypo-crp/devops/kypo-crp-tf-deployment
[8] https://gitlab.ics.muni.cz/muni-kypo-crp/devops/kypo-lite
Share with your friends and followers
Start blogging about your favorite technologies, reach more readers and earn rewards!
Join other developers and claim your FAUN account now!




User Popularity
76
Influence
8k
Total Hits
1
Posts

Read, Learn, Know, Teach
Hand curated newsletters for Developers, private Slack with like minded people, podcasts, job offers, news and more!

Only registered users can post comments. Please, login or signup.