Join us
@victoriamaslova ・ Nov 02,2021 ・ 18 min read・ 2k views ・ Originally posted on medium.com







In this article we will walk through automated hyperparameter tuning using Bayesian Optimization. Specifically, we will optimize the hyperparameters of a Gradient Boosting Machine using the Hyperopt library (with the Tree Parzen Estimator algorithm).
We will compare the results of random search (implemented manually) for hyperparameter tuning with the Bayesian model-based optimization method to try and understand how the Bayesian method works and what benefits it has over uninformed search methods.
You can easily find full code in my GitHub account. You are welcome!
Hyperopt

Hyperopt is one of several automated hyperparameter tuning libraries using Bayesian optimization. These libraries differ in the algorithm used to both construct the surrogate (probability model) of the objective function and choose the next hyperparameters to evaluate in the objective function. Hyperopt uses the Tree Parzen Estimator (TPE). Other Python libraries include Spearmint, which uses a Gaussian process for the surrogate, and SMAC, which uses a random forest regression.
Hyperopt has a simple syntax for structuring an optimization problem which extends beyond hyperparameter tuning to any problem that involves minimizing a function. Moreover, the structure of a Bayesian Optimization problem is similar across the libraries, with the major differences coming in the syntax (and in the algorithms behind the scenes that we do not have to deal with).
DATA
For this article, we will work with the Caravan Insurance Challenge dataset available on Kaggle. The objective is to determine whether or not a potential customer will buy an insurance policy by training a model on past data. This is a straightforward supervised machine learning classification task: given past data, we want to train a model to predict a binary outcome on testing data.
We implement the following code to see a distribution of Label.

Here is the result:
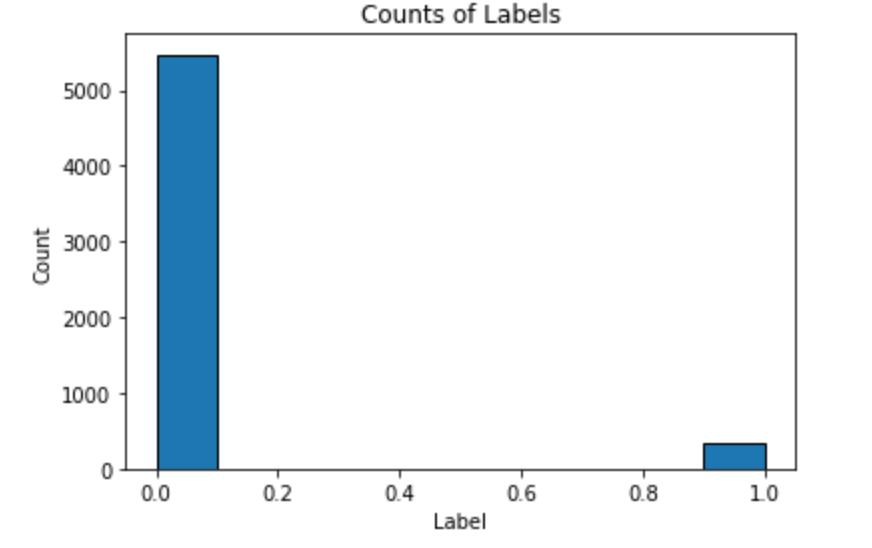
As we see, this is an imbalanced class problem: there are far more observations where an insurance policy was not bought (0) than when the policy was bought (1). Therefore, accuracy is a poor metric to use for this task. Instead, we will use the common classification metric of Receiver Operating Characteristic Area Under the Curve (ROC AUC). Randomly guessing on a classification problem will yield an ROC AUC of 0.5 and a perfect classifier has an ROC AUC of 1.0. For a better baseline model than random guessing, we can train a default Gradient Boosting Machine and have it make predictions.
Gradient Boosting Machine Default Model
We will use the LightGBM implementation of the gradient boosting machine. This is much faster than the Scikit-Learn implementation and achieves results comparable to extreme gradient boosting, XGBoost. For the baseline model, we will use the default hyperparameters as specified in LightGBM.

All we need to do is fit the model on the training data and make predictions on the testing data. For the predictions, because we are measuring ROC AUC and not accuracy, we have the model predict probabilities and not hard binary values.

That’s our metric to beat. Due to the small size of the dataset (less than 6000 observations), hyperparameter tuning will have a modest but noticeable effect on the performance (a better investment of time might be to gather more data!)
Random Search
First we will implement a common technique for hyperparameter optimization: random search. Each iteration, we choose a random set of model hyperparameters from a search space. Empirically, random search is very effective, returning nearly as good results as grid search with a significant reduction in time spent searching. However, it is still an uninformed method in the sense that it does not use past evaluations of the objective function to inform the choices it makes for the next evaluation.
Random search uses the following four parts, which also are used in Bayesian hyperparameter optimization:
Random search can be implemented in the Scikit-Learn library using RandomizedSearchCV, however, because we are using Early Stopping (to determine the optimal number of estimators), we will have to implement the method ourselves (more practice!). This is pretty straightforward, and many of the ideas in random search will transfer over to Bayesian hyperparameter optimization.
Domain for Random Search
Random search and Bayesian optimization both search for hyperparameters from a domain. For random (or grid search) this domain is called a hyperparameter grid and uses discrete values for the hyperparameters.
First, let’s look at all of the hyperparamters that need to be tuned.

Based on the default values, we can construct the following hyperparameter grid. It’s difficult to say ahead of time what choices will work best, so we will use a wide range of values centered around the default for most of the hyperparameters.
The subsample_dist will be used for the subsample parameter but we can't put it in the param grid because boosting_type=goss does not support row subsampling. Therefore we will use an if statement when choosing our hyperparameters to choose a subsample ratio if the boosting type is not goss.

Let’s look at two of the distributions, the learning_rate and the num_leaves. The learning rate is typically represented by a logarithmic distribution because it can vary over several orders of magnitude. np.logspace returns values evenly spaced over a log-scale (so if we take the log of the resulting values, the distribution will be uniform.)
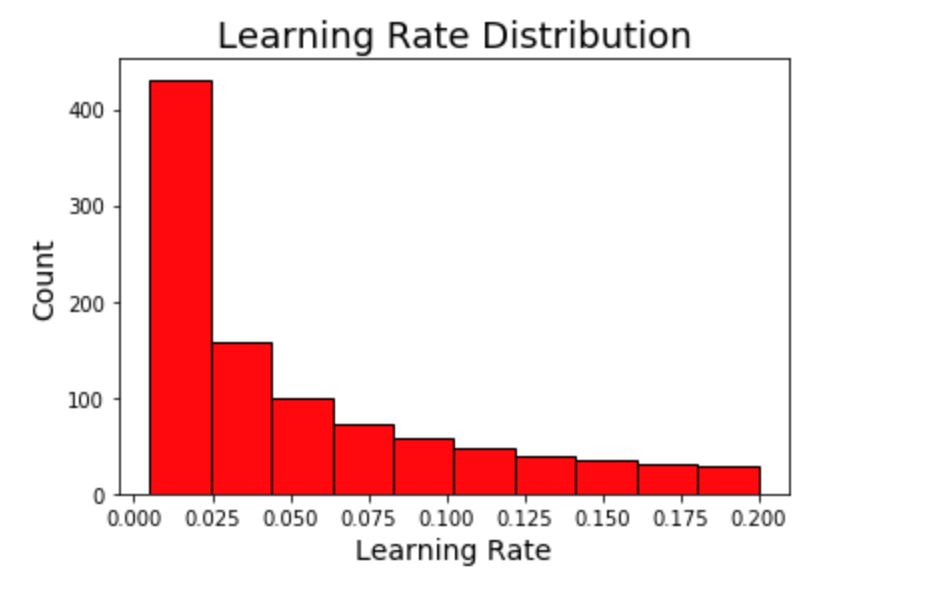
Smaller values of the learning rate are more common with the values between 0.005 and 0.2. The width of the domain is fairly large indicating a large amount of uncertainty on our part about the optimal value (which we hope is somewhere in the grid)!

The number of leaves is a simple uniform domain.
Sampling from Hyperparameter Domain
Let’s look at how we sample a set of hyperparameters from our grid using a dictionary comprehension.
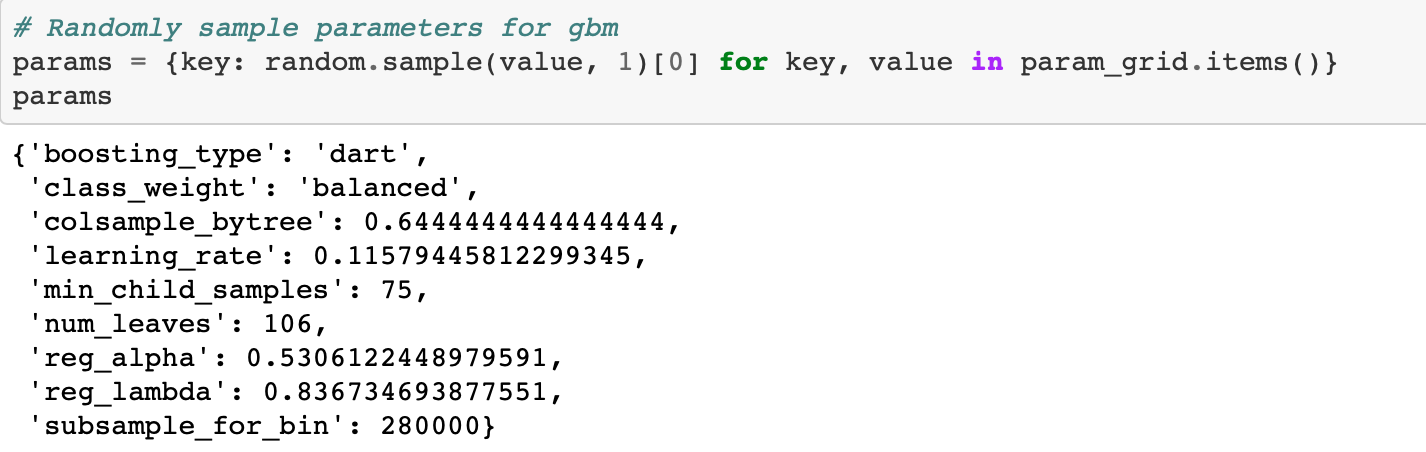
We set the subsample to 1.0 if boosting type is goss which is the same as not using any subsampling. (Subsampling is when we train on a subset of the rows (observations) rather than all of them. This technique is also referred to as bagging for “bootstrap aggregating”).
Cross Validation with Early Stopping in LightGBM
The scikit-learn cross validation api does not include the option for early stopping. Therefore, we will use the LightGBM cross validation function with 100 early stopping rounds. To use this function, we need to create a dataset from our features and labels.
The cv function takes in the parameters, the training data, the number of training rounds, the number of folds, the metric, the number of early stopping rounds, and a few other arguments. We set the number of boosting rounds very high, but we will not actually train this many estimators because we are using early stopping to stop training when the validation score has not improved for 100 estimators.

We have our domain and our algorithm which in this case is random selection. The other two parts we need for an optimization problem are an objective function and a data structure to keep track of the results (these four parts will also be required in Bayesian Optimization).
Tracking the results will be done via a dataframe where each row will hold one evaluation of the objective function.
Objective Function
The objective function will take in the hyperparameters and return the validation loss (along with some other information to track the search progress). We already choose our metric as ROC AUC and now we need to figure out how to measure it. We can’t evaluate the ROC AUC on the test set because that would be cheating. Instead we must use a validation set to tune the model and hope that the results translate to the test set.
A better approach than drawing the validation set from the training data (thereby limiting the amount of training data we have) is KFold cross validation. In addition to not limiting the training data, this method should also give us a better estimate of generalization error on the test set because we will be using K validations rather than only one. For this example we will use 10-fold cross validation which means testing and training each set of model hyperparameters 10 times, each time using a different subset of the training data as the validation set. The objective function will return a list of information, including the validation AUC ROC. We also want to make sure to save the hyperparameters used so we know which ones are optimal (or the best out of those we tried).
In the case of random search, the next values selected are not based on the past evaluation results, but we clearly should keep track so we know what values worked the best! This will also allow us to contrast random search with informed Bayesian optimization.

Random Search Implementation
Now we can write a loop to iterate through the number of evals, each time choosing a different set of hyperparameters to evaluate. Each time through the function, the results are saved to the dataframe. (The %%capture magic captures any outputs from running a cell in a Jupyter Notebook. This is useful because the output from a LightGBM training run cannot be suppressed.)

And we got the following output:

Random Search Performance
As a reminder, the baseline gradient boosting model achieved a score of 0.71 on the training set. We can use the best parameters from random search and evaluate them on the testing set.
What were the hyperparameters that returned the highest score on the objective function?

The estimators key holds the average number of estimators trained with early stopping (averaged over 10 folds). We can use this as the optimal number of estimators in the gradient boosting model.

A modest gain over the baseline. Using more evaluations might increase the score, but at the cost of more optimization time. We also have to remember that the hyperparameters are optimized on the validation data whigh may not translate to the testing data.
Now, we can move on to Bayesian methods and see if they are able to achieve better results.
Bayesian Hyperparameter Optimization using Hyperopt
For Bayesian optimization, we need the following four parts:
We already used all of these in random search, but for Hyperopt we will have to make a few changes.
Objective Function
This objective function will still take in the hyperparameters but it will return not a list but a dictionary. The only requirement for an objective function in Hyperopt is that it has a key in the return dictionary called "loss" to minimize and a key called "status" indicating if the evaluation was successful.
If we want to keep track of the number of iterations, we can declare a global variables called ITERATION that is incremented every time the function is called. In addition to returning comprehensive results, every time the function is evaluated, we will write the results to a new line of a csv file. This can be useful for extremely long evaluations if we want to check on the progress (this might not be the most elegant solution, but it's better than printing to the console because our results will be saved!)
The most important part of this function is that now we need to return a value to minimize and not the raw ROC AUC. We are trying to find the best value of the objective function, and even though a higher ROC AUC is better, Hyperopt works to minimize a function. Therefore, a simple solution is to return 1 — ROC (we did this for random search as well for practice).
Although Hyperopt only needs the loss, it's a good idea to track other metrics so we can inspect the results. Later we can compare the sequence of searches to that from random search which will help us understand how the method works.
Domain Space
Specifying the domain (called the space in Hyperopt) is a little trickier than in grid search. In Hyperopt, and other Bayesian optimization frameworks, the domian is not a discrete grid but instead has probability distributions for each hyperparameter. For each hyperparameter, we will use the same limits as with the grid, but instead of being defined at each point, the domain represents probabilities for each hyperparameter. This will probably become clearer in the code and the images.

First we will go through an example of the learning rate. Again, we are using a log-uniform space for the learning rate defined from 0.005 to 0.2 (same as with the grid from random search.) This time, when we graph the domain, it’s more accurate to see a kernel density estimate plot than a histogram (although both show distributions).
We can visualize the learning rate by sampling from the space using a Hyperopt utility. Here we plot 10000 samples.


The number of leaves is again a uniform distribution. Here we used quniform which means a discrete uniform (as opposed to continuous).
Conditional Domain
In Hyperopt, we can use nested conditional statements to indicate hyperparameters that depend on other hyperparameters. For example, we know that goss boosting type cannot use subsample, so when we set up the boosting_type categorical variable, we have to se the subsample to 1.0 while for the other boosting types it's a float between 0.5 and 1.0 Let's see this with an example:

We need to set both the boosting_type and subsample as top-level keys in the parameter dictionary. We can use the Python dict.get method with a default value of 1.0. This means that if the key is not present in the dictionary, the value returned will be the default (1.0).
Complete Bayesian Domain
Now we can define the entire domain. Each variable needs to have a label and a few parameters specifying the type and extent of the distribution. For the variables such as boosting type that are categorical, we use the choice variable. Other variables types include quniform, loguniform, and uniform. For the complete list, check out the documentation for Hyperopt.

Optimization Algorithm

Although this is the most technical part of Bayesian optimization, defining the algorithm to use in Hyperopt is simple. We will use the Tree Parzen Estimator which is one method for constructing the surrogate function and choosing the next hyperparameters to evaluate.
Tree-Structured Parzen Estimator (TPE) algorithm is designed to optimize quantization hyperparameters to find quantization configuration that achieve an expected accuracy target and provide best possible latency improvement. TPE is an iterative process that uses history of evaluated hyperparameters to create probabilistic model, which is used to suggest next set of hyperparameters to evaluate.
Results History
The final part is the result history. Here, we are using two methods to make sure we capture all the results:
Trials object that stores the dictionary returned from the objective function
The Trials object will hold everything returned from the objective function in the .results attribute. It also holds other information from the search, but we return everything we need from the objective.

Every time the objective function is called, it will write one line to this file. Running the cell above does clear the file though.
Bayesian Optimization
We have everything in place needed to run the optimization. First we declare the global variable that will be used to keep track of the number of iterations. Then, we call fmin passing in everything we defined above and the maximum number of iterations to run.

The .results attribute of the Trials object has all information from the objective function. If we sort this by the lowest loss, we can see the hyperparameters that performed the best in terms of validation loss.

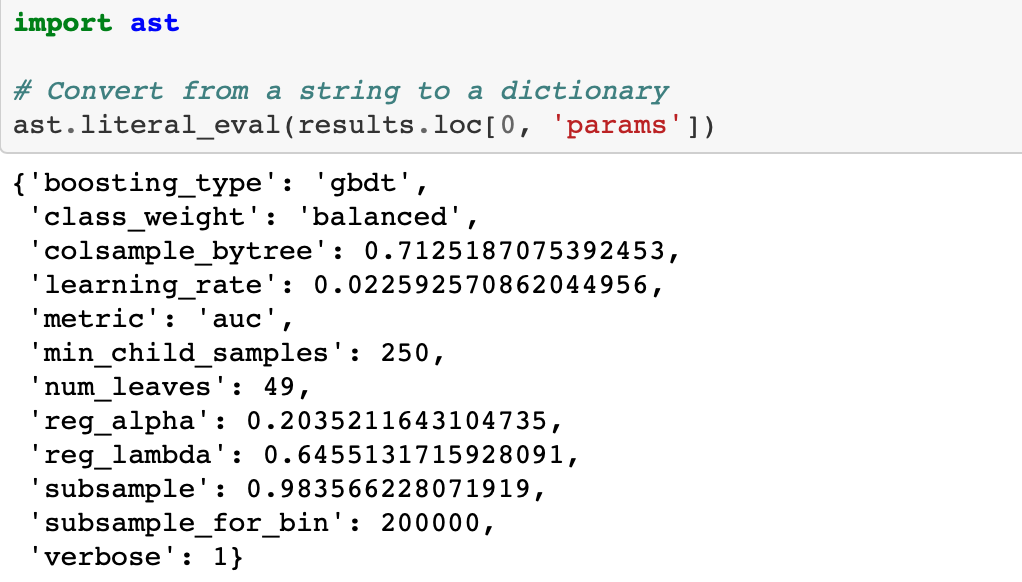
We can also access the results from the csv file (which might be easier since it’s already a dataframe).

For some reason, when we save to a file and then read back in, the dictionary of hyperparameters is represented as a string. To convert from a string back to a dictionary we can use the ast library and the literal_eval function.
Evaluate Best Results
Now for the moment of truth: did the optimization pay off? For this problem with a relatively small dataset, the benefits of hyperparameter optimization compared to random search are probably minor (if there are any). Random search might turn up a better result in fewer iterations simply becuase of randomness!
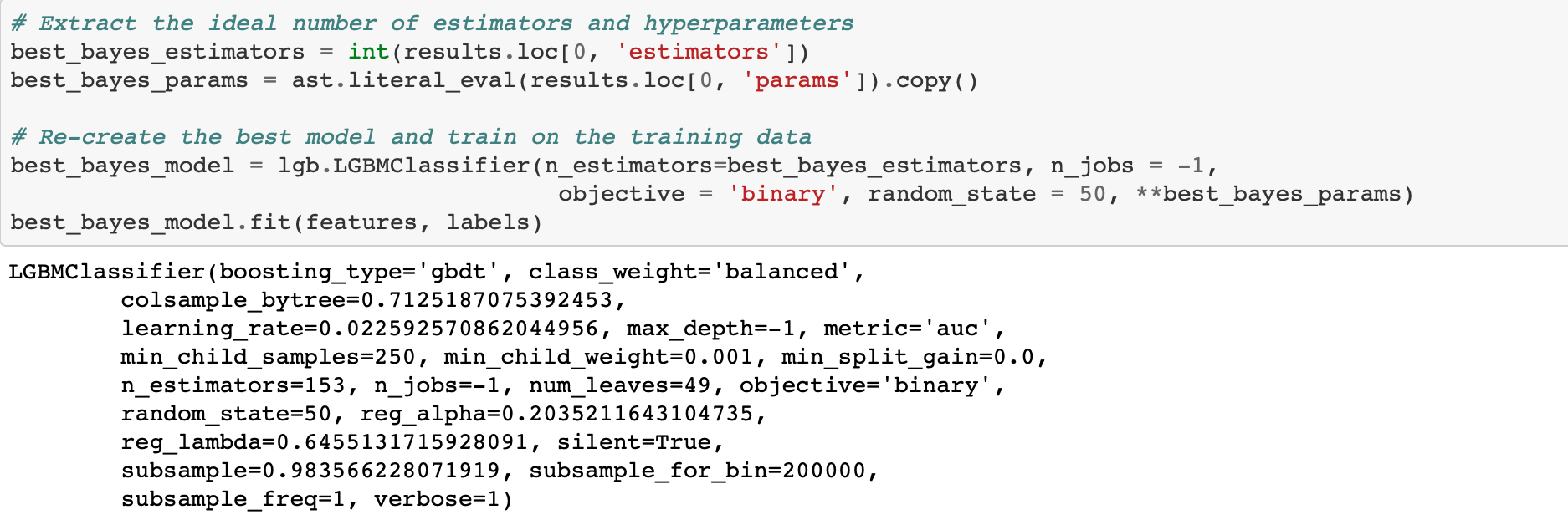

The Bayes Optimization scored slightly higher on the test data ROC AUC (here unlike the loss, higher is better) but also took more iterations to reach the best score (if the notebook is re-run, the results may change). The Bayesian Optimization also does better in terms of the validation loss (1 — ROC AUC) scoring 0.229 compared to 0.231. Due to the small differences, it’s hard to say that Bayesian Optimization is better for this particular problem. As with any other machine learning technique, the effectiveness of Bayesian Optimization will be problem dependent. For this problem, we see a slight benefit but it is also possible that random search may find a better set of hyperparameters.
Comparison to Random Search
Comparing the results to random seach both in numbers and figures can help us understand how Bayesian Optimization searches work. First, we can look at the best hyperparameters (as determined from the validation error) from both searches.
We can compare the “best” hyperparameters found from both search methods. It’s interesting to compare the results because they suggest there may be multiple configurations that yield roughly the same validation error.

The top row is the Bayesian Optimization and the bottom row is random search.
Visualizing Hyperparameters
One interesting thing we can do with the results is to see the different hyperparameters tried by both random search and the Tree Parzen Estimator. Since random search is choosing without regards to the previous results, we would expect that the distribution of samples should be close to the domain space we defined (it won’t be exact since we are using a fairly small number of iterations). On the other hand, the Bayes Optimization, if given enough time, should concetrate on the “more promising” hyperparameters.
In addition to a more concentrated search, we expect that the average validation loss of the Bayesian Optimization should be lower than that on the random search because it chooses values likely (according to the probability model) to yield lower losses on the objective function. The validation loss should also decrease over time with the Bayesian method.
First we will need to extract the hyperparameters from both search methods. We will store these in separate dataframes.


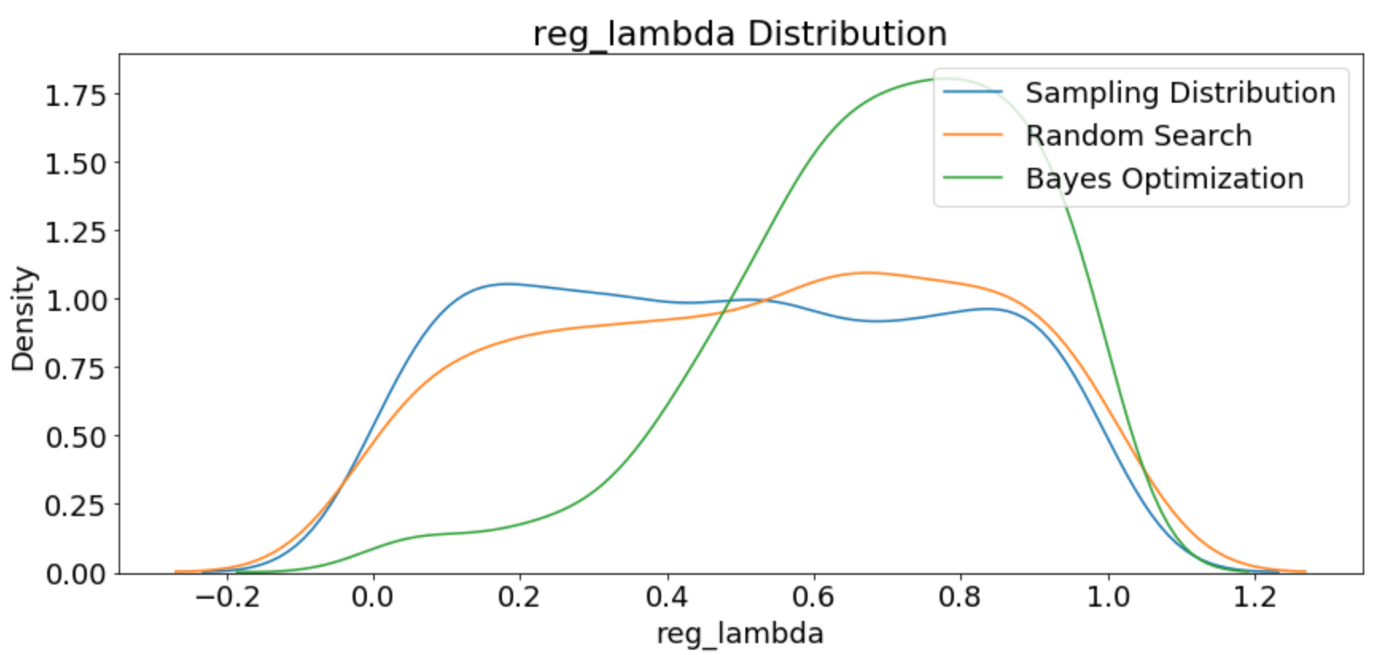
Learning Rates
The first plot shows the sampling distribution, random search, and Bayesian optimization learning rate distributions.


Boosting Type
Random search should use the boosting types with the same frequency. However, Bayesian Optimization might have decided (modeled) that one boosting type is better than another for this problem.
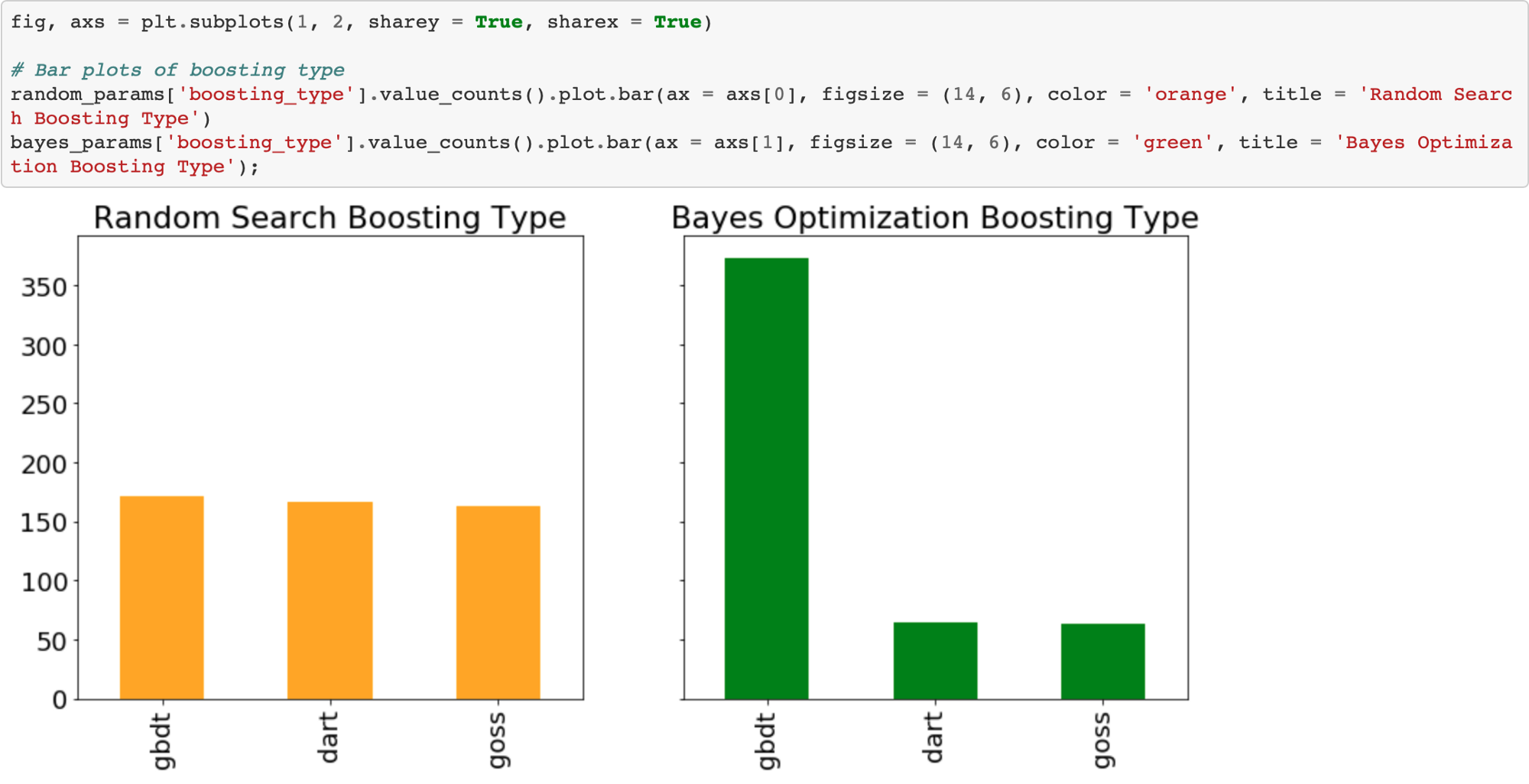
Sure enough, the Bayesian Optimization tried the gradient boosted decision tree boosting type much more than the other two. We could use this information to inform subsequent searches for the best hyperparameters by focusing on a smaller domain.
Plots of All Numeric Hyperparameters








The final graph shows that the validation loss for Bayesian Optimization tends to be lower than than from Random Search. This should give us confidence the method is working correctly. Again, this does not mean the hyperparameters found during Bayesian Optimization are necessarily better for the test set, only that they yield a lower loss in cross validation.
Evolution of Hyperparameters Searched
We can also plot the hyperparameters over time (against the number of iterations) to see how they change for the Bayes Optimization. First we will map the boosting_type to an integer for plotting.

There is not much change over time for this hyperparameter: gdbt is dominant for the entire stretch.

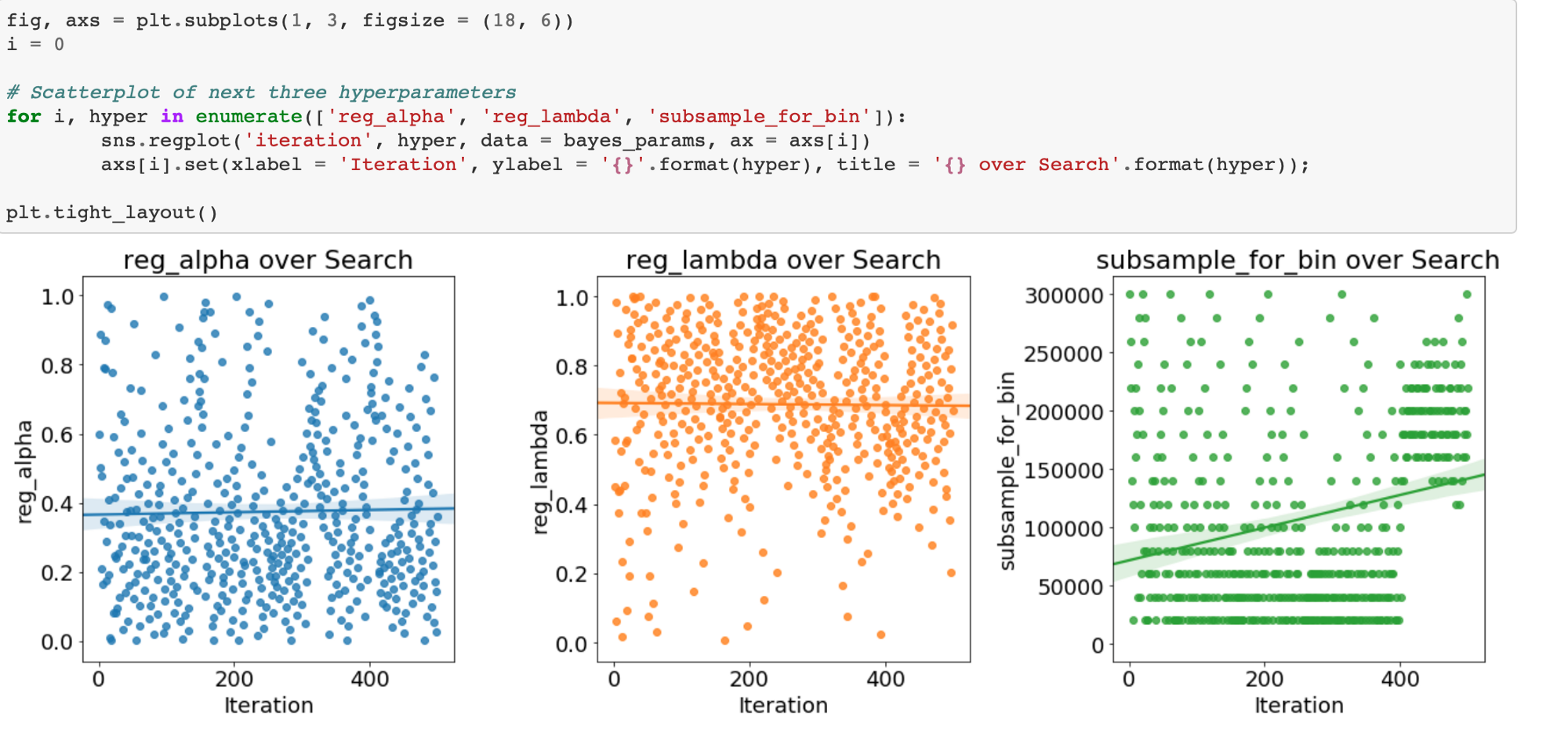
If there are trends in these plots, we can use them to inform subsequent searches. We might even want to use grid search focusing on a much smaller region of hyperparameter space based on the Bayesian Optimization results.
Validation Losses
Finally, we can look at the losses recorded by both random search and Bayes Optimization. We would expect the average loss recorded by Bayes Optimization to be lower because this method should spend more time in promising regions of the search space.

It does appear that the validation ROC AUC for the Bayesian optimization is higher than that for Random Search. However, as we have seen, this does not necessarily translate to a better testing score!
Bayesian optimization should get better over time. Let’s plot the scores against the iteration to see if there was improvement.

Conclusions
In this article, we saw how to implement automated hyperparameter tuning with Bayesian Optimization methods. We used the open-source Python library Hyperopt with the Tree Parzen Estimator to optimize the hyperparameters of a gradient boosting machine.
Bayesian model-based optimization can be more efficient than random search, finding a better set of model hyperparameters in fewer search iterations (although not in every case). However, just because the model hyperparameters are better on the validation set does not mean they are better for the testing set! For this training run, Bayesian Optimization found a better set of hyperparamters according to the validation and the test data although the testing score was much lower than the validation ROC AUC. This is a useful lesson that even when using cross-validation, overfitting is still one of the top problems in machine learning.
Bayesian optimization is a powerful technique that we can use to tune any machine learning model, so long as we can define an objective function that returns a value to minimize and a domain space over which to search. This can extend to any function that we want to minimize (not just hyperparameter tuning). Bayesian optimization can be a significant upgrade over uninformed methods such as random search and because of the ease of use in Python are now a good option to use for hyperparameter tuning. As with most subjects in machine learning, there is no single best answer for hyperparameter tuning, but Bayesian optimization methods should be a tool that helps data scientists with the tedious but necessary task of model tuning!
Share with your friends and followers
Join other developers and claim your FAUN account now!

Influence
Total Hits
Posts

Hand curated newsletters for Developers, private Slack with like minded people, podcasts, job offers, news and more!


