







One of the great chapters of Google’s Site Reliability Engineering (SRE) second book is chapter 5 — Alerting on SLOs (Service Level Objectives). This chapter takes you on a comprehensive journey through several setups of alerts on SLOs, starting with the simplest non-optimized one and by iterating through several setups reach the ultimate one, which is optimized w.r.t to the main four alerting attributes: recall, precision, detection time and reset time.
To summarize: For each SLO, the ultimate alerting setup, Multiwindow, Multi-Burn-Rate Alert, sets several thresholds based on different error budget consumptions: 2 %, 5 %, and 10 %, on relatively long windows of 1,6 and 72 hours respectively. This setup leads to both high recall and high precision while keeping the detection time relatively short. To minimize the reset time, the setup defines short windows (1/12 of the long ones) such the alert fires only if both the long window and the short one cross over the threshold.
However, after exploring this solution on different Service Level Indicators (SLIs) and against some scenarios, it seems that it has some limitations. In this post, I will elaborate on those limitations and the reasons for their existence. To address them, I propose a simple but significant improvement to the above setup, which makes it generalize better, specifically for varying-traffic services and for low SLO scenarios.
Definitions
Before we dive into the implementation of the above solution, and for the sake of clarity in the rest of the post, let’s review the following terms and their definitions:
- SLI - Service Level Indicator. Expressed as the ratio between the number of good events to the total number of events in a given time window. For example, for an availability SLI of a web application, all the successful HTTP requests will be considered as good events.

taken from Google’s Site Reliability Engineering course in Coursera
- SLO -Service Level Objective. A target on the SLI. Notice that the above definition of SLI implies that we always want our SLIs to be as high as possible or not to pass pre-defined lower bound. The SLO is this lower bound. An SLO must have a time window on which the SLO is defined. Common choices are week, 28, or 30 days. For example, 99.9% 30-day availability SLO means that we want our availability SLI on any 30-day window will not to fall below 99.9 %.
- Actual Error Rate (or simply “error rate”) - The complementary of the SLI, namely the ratio between the number of bad events to the total number of events.
- SLO Error Rate - The complementary of the SLO. Define an upper bound on the actual error rate. For example, the SLO error rate of 99.9 % SLO is 0.1 %.
- Error Budget - The number of allowable bad events in a given SLO time window. The error budget can be measured on a given time window to set a starter achievable SLO or to be calculated by multiplying the total number of events in an SLO time window by the SLO error rate, in the case of pre-defined SLO. Notice that the above definition of error budget is taken from chapter 5 — Alerting on SLOs, though in other sources (including Google’s ones) you may find the term “error budget” used as the above-defined SLO error rate or as allowable downtime minutes.
- Burn Rate - How fast, relative to the SLO, the service consumes the error budget. The Figure below explains it well for 30-day SLO:
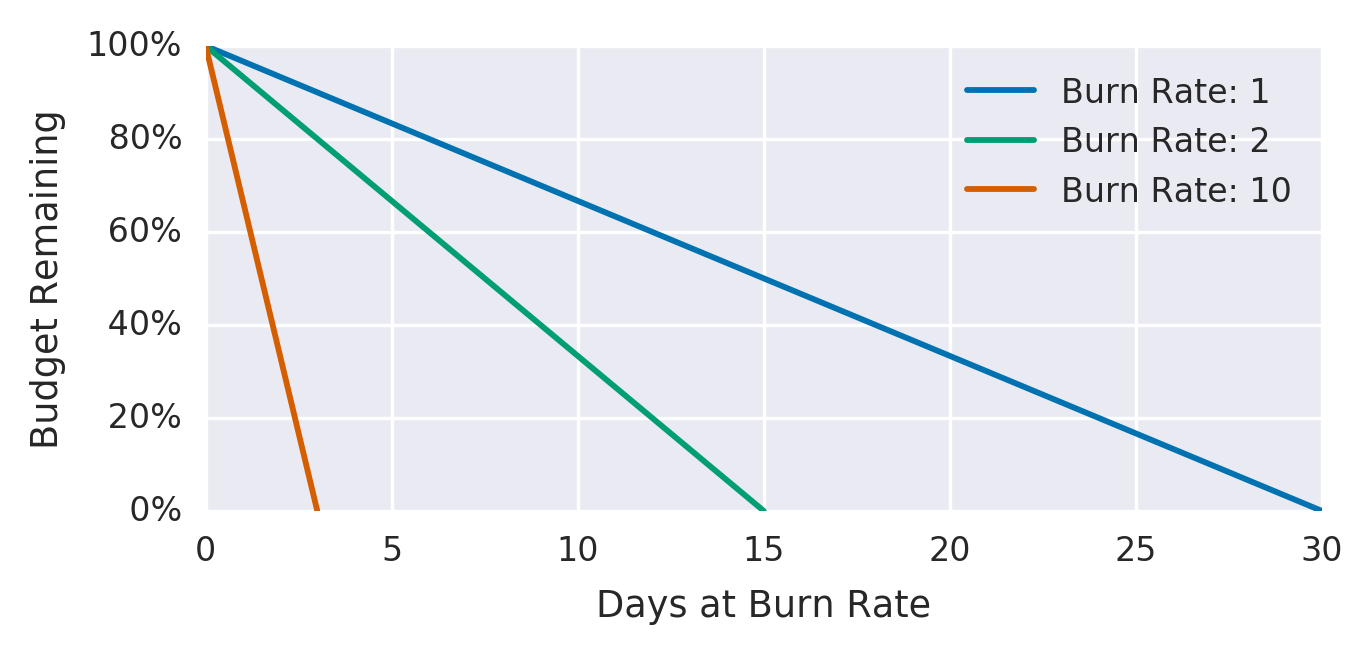
taken from chapter 5 — Alerting on SLOs
we can see that with a burn rate of 2 we consume all the budget in 15 days, while with a burn rate of 1 only 50 % of the budget is consumed in this period.
Burn Rate Thresholds
It is important to note that the percentage of error budget consumption is the starting point for each window defined in the discussed alerting setup, as this is the most intuitive measure to reason about: “notify me only if we pass 2% error budget consumption in 1 hour or 5 % error budget in 6 hours”. However, it is taken for granted in the chapter that the metric we are alerting on is not the actual percentage of error budget consumption but rather the error rate, hence some transformation is needed.
Indeed, the implementation of the above alerting solution is done by transforming the different error budget consumptions (for each alerting window) into burn rates by the following equation:

where ‘period’ is the period on which the SLO is defined (usually 28 or 30 days). Based on this transformation, the threshold of each window is defined as the multiplication of the SLO error rate by the burn rate calculated for this window.
For example, consumption of 2 % of a 30-day error budget in only one hour is translated by the equation above to a burn rate of 14.4. Multiplying this burn rate by the SLO error rate gives the desired threshold: For 99.9 % SLO, we will get a threshold of 14.4 × 0.1 % = 1.44 %, meaning fire alert only if the error rate in the last hour is greater than 1.44 %.
In the same manner, we get a burn rate of 6x for 5 % budget consumption in 6 hours window and a burn rate of 1x for 10% budget consumption in 3 days window.
Does it fit all SLIs?
The SLI used as an example along the chapter is availability SLI but it clarified there that:
“error budgets” and “error rates” apply to all SLIs, not just those with “error” in their name.
Even though, it seems not so trivial to implement the above solution on other SLIs, specifically for latency SLI. Fortunately, there is a great session by Björn Rabenstein that elaborates on how this solution can be implemented on latency SLI too.
Does it fit all SLOs?
Chapter 5 uses as an example an SLO of 99.9 % and Björn Rabenstein takes examples of 99.9% and 99.5 % in his session. The lowest SLO I found as a demonstration of this alerting setup was in
Yuri Grinshteyn's post where he used an availability SLO of 95 %. But even if we take this relatively low SLO we still can alert on the highest burn rate of this setup: 14.4x for the 1-hour window, since 14.4 × 5 % = 70 %. Indeed, 70 % is a very high threshold, but taking into account that this relatively low SLO defines allowable 2,160 (!) minutes of downtime in a 30-days window, it makes complete sense. The math doesn’t lie: only if the actual error rate will be higher than 70 % in one hour we will get consumption of 2 % of the error budget and below that we don’t want (or need) to be notified unless this occurs on longer time windows, which will be caught by the other 2 longer windows (that are defined on lower burn rates).
Typical Latency SLOs
As opposed to availability SLOs wherein most of the cases will be defined on the range between 2 nines (99 %) to 5 nines (99.999 %), latency SLOs can be on lower percentiles of the total requests, particularly when we want to capture both the typical user experience and the long tail, as recommended in chapter 2 of the SRE workbook, Implementing SLOs. In this chapter, two latency SLOs are defined:
- 90 % of requests < 450 ms
- 99 % of requests < 900 ms
The First Limitation: SLO’s Lower Bound
Applying a 14.4x burn rate to the second one is straightforward: The SLO error rate is 1%, hence the threshold is 14.4 %. But if we try to apply this burn rate to the first one… well, I suppose you already did the math: we get a threshold of 144 %, meaning that even if all the requests in the last hour are slower than 450 ms, we still didn’t consume 2 % of the error budget but only ~1.39 % (since the burn rate is only 10x).
So what can we do? We still want to use the powerful mechanism of alerting on different error budget consumptions. However, the above scenario reveals a lower bound on the minimal SLOs we can alert on using this solution. This lower bound can be calculated easily as 100% – 100%÷14.4 ≅ 93.06 %. Of course, we cannot limit ourselves to this bound, especially when dealing with latency SLOs.
The 2nd Limitation: Services With Varying Traffic
Notice that the above limitation stems from the fact that we not alerting directly on the error budget but rather on the error rate which is expressed in percentages. On one hand, it seems the natural choice because we care about our SLOs, which are percentages by definition. On the other hand, alerting on percentages not only limits our ability to alert on SLOs lower than 93 % but also can introduce another limitation for all those services with varying traffic volumes (night vs day, business days vs weekends, etc.).
The problem of using this solution with varying-traffic services is that we can easily get false alarms or miss real incidents. Specifically, in service with high traffic at day and low traffic at night, we can get a lot of false alarms at night, since even if we pass the error rate threshold (which is expressed in percent), probably the absolute number of bad requests will be lower or much lower than 2 % of the error budget. On the contrary, at peak hours, where the number of requests can be much higher than the average, we can still be under the error rate percentage threshold but exceed the 2 % error budget threshold.
The Solution: Alert Directly on Error Budgets
Indeed, chapter 5 mentions the case of services with low or varying traffic and suggests some solutions such as generating artificial traffic or combining several services into a larger one for monitoring purposes. However, the accompanying discussion is focused mainly on low-traffic services and not on those with varying traffic. Moreover, these proposed solutions may solve only the second problem and lead to unnecessary overhead.
My proposed solution is surprisingly simple and solves both problems: Instead of alerting on the error rate, alert directly on the error budget!
Why
- Solving Problem 1 - SLO lower bound: Notice that this problem stems from the transformation (through the burn rate) of a natural number - the error budget, which is unbounded, to a ratio - the error rate, which is bounded in the range (0, 100 %]. Since we alert directly on the error budget we remain in the unbounded range and the 93 % SLO lower bound becomes irrelevant.
- Solving Problem 2 - services with varying traffic: By alerting directly on the error budget we’ll get alerts in low-traffic periods only where there are enough requests and a very high error rate, hence decreasing the number of false alarms. On the other hand, at peak hours we won’t miss real incidents since the alert will fire immediately when we reach 2 % of the error budget, even if the error rate is relatively small (less than 14.4x).
How
To demonstrate how we can alert on error budget let’s return to the example of 30-day latency SLO of 90% of requests < 450 ms. We can easily measure the total number of requests in the past 30 days and multiply it by the complementary of the SLO, 10 %, to get the error budget which is the total number of allowable bad requests (slower than 450 ms) in the above period. For example, suppose the total number of requests in the last 30 days is 1,000,000, then we allow 100,000 requests to be slower than 450 ms in 30 days period. 2 % of this error budget is 2,000 requests and this will be our threshold for the 1-hour window, namely, we will alert only if more than 2000 requests in the last hour and more than 167 requests in the last 5 minutes are slower than 450 ms.
Now, let’s implement it using Prometheus syntax:
Measuring the total number of requests in the past 30 (or 28) days can be done by:
To use it in our threshold expression we should set it as a recording rule:
Now, since we want to alert on the error budget, which is the total absolute number of allowable bad requests in the SLO period, we need a recording rule to count those bad requests for all long and short windows. For example, for the 1-hour window the recording rule will be as follows:
where we simply subtract the number of requests that are faster than 450 ms from the total number of requests.
Now all is left is to create alerting rule on it :
where we calculate 10 % of the total number of requests to get the error budget and multiply it by 0.02 to get the desired threshold of 2 % of the error budget. Notice that for the short window I divided the 2 % by 12 since this is the ratio between all the long windows to the short ones.
Conclusion
In this post, I presented two limitations in Google’s solution for alerting on SLOs as detailed in chapter 5 in Google’s SRE workbook. Those limitations are expressed at relatively low SLOs and/or services with varying traffic. To solve those problems I suggested alerting directly on the error budget as a simple yet powerful solution that eliminates both of those limitations with no additional effort.
In the next part I will show mathematically why Google’s solution is not suitable for varying-traffic services and how we can still alert on error rate, but do it correctly.
Thanks to Ofri Oren,
Amiel Botbol, and Omer Stark for their reviews.
Share with your friends and followers
Start blogging about your favorite technologies, reach more readers and earn rewards!
Join other developers and claim your FAUN account now!





User Popularity
44
Influence
4k
Total Hits
2
Posts

Read, Learn, Know, Teach
Hand curated newsletters for Developers, private Slack with like minded people, podcasts, job offers, news and more!

Only registered users can post comments. Please, login or signup.