The Slow Collapse of MkDocs
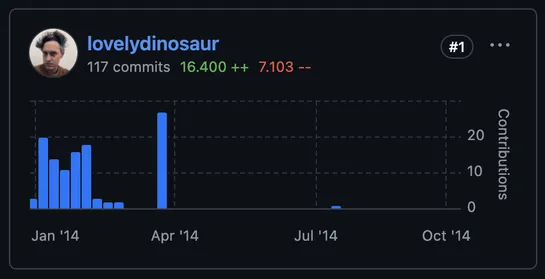
On March 9, 2026 a former maintainer grabbed the PyPI package forMkDocs. The original author's rights got stripped. Ownership snapped back within six hours. Core development stalled for 18 months.Material for MkDocswent into maintenance. The ecosystem splintered intoProperDocs,MaterialX, andZensical.. read more