







Let’s see what is VACUUM in PostgreSQL, how it’s useful, and how to improve your database performance.
Storage Basics
Before diving into vacuuming, it's important to first understand the fundamentals of data storage in PostgreSQL. While we’ll explain how data is represented internally, we won’t cover every aspect of storage, such as shared memory or buffer pools.
Let's start by examining a table. At its core, data is stored in data files. Each data file is divided into pages, typically 8 kilobytes in size. This structure allows the database to manage growing datasets efficiently without performance issues. PostgreSQL handles these pages individually, so it doesn’t need to load an entire table into memory during a read operation. Internally, these pages are often referred to as blocks, and we’ll use the terms interchangeably throughout this discussion.
Each data page contains the following components:
Header: 24 bytes long, containing maintenance information for transaction management and pointers to other sections for easy access.
Line pointers: References to the actual tuples holding the data.
Free space
Tuples
Now, let’s look at a diagram:
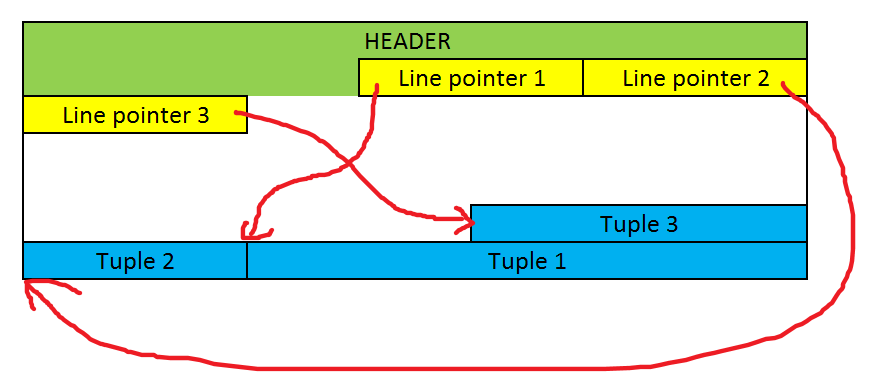
As shown, tuples are stored starting from the end of the page and grow backward. Thanks to the line pointers, each tuple can be easily located, and new tuples can be added seamlessly to the file. Every tuple is identified by a Tuple Identifier (TID), which is a pair of numbers: one representing the block (or page) number and the other representing the line pointer number within that page. Here’s what a typical tuple looks like:

As shown, each tuple consists of a header and the actual data. The header contains metadata and several important fields related to transaction management:
t_xmin: Stores the transaction identifier of the transaction that inserted the tuple.
t_xmax: Stores the transaction identifier of the transaction that deleted or updated the tuple. If the tuple hasn’t been deleted or updated, this field will hold a value of 0.
The transaction identifier is a number that increments with every new transaction. The fields t_xmin and t_xmax are essential for determining the visibility of a tuple during a transaction. Essentially, each transaction receives a snapshot that defines which tuples are visible and which should be ignored. This is crucial for Multi-Version Concurrency Control.
Multi-Version Concurrency Control
Multi-Version Concurrency Control (MVCC) enables the database to handle multiple transactions simultaneously, enhancing performance. Instead of blocking transactions when they attempt to access the same data, MVCC allows multiple versions of each entity to exist concurrently, only rolling back transactions that introduce conflicting changes.
This method is especially advantageous when transactions involve modifying unrelated entities or primarily reading data. In such cases, there is seldom a need to roll back a transaction due to invalid changes. Additionally, transactions can proceed independently without waiting for others, which is a key principle in how PostgreSQL manages its data.
However, this approach makes modifications slightly more difficult. Since we don’t want to stop the transactions, we somehow need to control which changes are visible to which transactions. This is determined based on t_xmin and t_xmax fields and visibility maps. This may lead to a situation in which many versions of the same row exist in the database. Let’s see how that’s possible.
Let’s create a table and insert one row into it:
CREATE TABLE test (id INT)
INSERT INTO test VALUES (1)
Let’s now start the first transaction and read the table, but don’t commit the transaction yet.
BEGIN TRANSACTION
SELECT * FROM test
This returns value 1. Let’s now start another transaction that does the following:
BEGIN TRANSACTION
UPDATE test SET id = 2
SELECT * FROM test
This returns value 2. However, if we now return to the first transaction and rerun the select statement, then we will still get value 1. This indicates that there are two versions of the same row with different visibility to support different transactions.
This is achieved by introducing duplicates and using t_xmin and t_xmax fields. When we first insert the value, the t_xmax of the entity is set to 0 which indicates there is no newer version yet. Later, when we run the UPDATE statement, the t_xmax is changed to indicate the last transaction that should see this row, and a new row is inserted into the same table with t_xmin set to the latest transaction number.
This poses two interesting questions:
If the second transaction is rolled back, what happens with the newer row?
On the other hand, what happens with the older row if the second transaction is committed?
Both these situations lead to so-called dead tuples. A dead tuple is a tuple that is not visible to any transaction. It was either removed or updated. Dead tuples degrade performance by wasting disk space and making the database engine read more data when running transactions.
Dead tuples are not removed immediately. Nothing happens when we commit a transaction that creates dead tuples (by deleting rows or updating them) and the modified data is ready to be used by other transactions. Old tuples are only marked for deletion and we need to remove them periodically. This leads to the process called vacuuming.
Vacuuming
As we saw above, we need to periodically curate our tables to remove dead tuples. This is done by vacuuming which takes care of removing dead tuples to recover the wasted disk space. Vacuuming became a periodic maintenance task over the years that does much more than just removing the dead tuples. It does the following:
Updates statistics used by the PostgreSQL query planner
Updates the visibility map used by the index-only scans
Protects the server from the loss of ancient data due to transaction wraparound
Recovers the disk space for later reuse
Returns the space to the operating system if possible
Compacts tables by rewriting them
Vacuuming runs in two modes: regular and full. Regular vacuuming doesn’t try to minimize disk space usage but wants to achieve stability and steady usage of disk space. This should be sufficient for most of our day-to-day operations and we should rarely need a full vacuuming that shrinks the tables.
Vacuuming runs automatically and can be scheduled or run on demand with VACUUM or VACUUM FULL. A typical approach is to let it run automatically or schedule a database-wide VACUUM once a day during an off-peak period (typically at night).
When it comes to updating the statistics, the vacuuming daemon automatically runs ANALYZE command whenever it decides that the content of a table has changed sufficiently. This may not be enough if we modify fewer rows or if we modify important columns (as the daemon does not know the distribution of the values). Therefore, we may need to manually analyze the tables to keep the statistics up to date. This may be especially useful after batch-loading many rows. We can analyze some tables only or even some columns.
However, the vacuuming daemon does not analyze foreign tables. If we need statistics for them, then we need to analyze them manually. Similarly, the daemon does not analyze the parent partition when children change. We need to analyze them manually.
Yet another thing that vacuuming does is update the visibility map. This is needed to speed up the index-only scans. The auto-vacuuming daemon takes care of that automatically.
Transaction wraparound
The last activity that vacuuming takes care of is preventing transaction ID wraparound issues. MVCC depends on the transaction ID (XID) numbers that determine the visibility of rows. Each XID is simply a 32-bit number. In a database with plenty of transactions, we may cause the XID to overflow or wrap around.
When this happens, we may run into issues. Without going much into detail, the row is visible if it had been created before the current transaction started. To determine that, we compare if the t_xmin is less than the current XID. This works as long as XID numbers increase. However, once the transaction number overflows, it starts counting from zero again. Therefore, we may incorrectly conclude that some rows shouldn’t be visible as their t_xmin is greater than the current XID. This is incorrect.
To fix that, vacuuming marks rows as frozen which means that they were created sufficiently far in the past to be handled differently. When determining if a row should be visible, we don’t compare t_xmin for frozen rows, but we just assume they are always created in the past.
The remaining question is which rows should we consider frozen. This is determined by the vacuum_freeze_min_age parameter which defaults to 50 million. If a row was created 50 million transactions ago, then the vacuuming daemon turns the row into a frozen one. We may want to increase this parameter to make the freezing less often.
Transaction wraparound may cause the database to shut down and data loss. We should prevent this from happening by curating our databases often.
Seeing It In Action
Different vacuuming activities kick in based on different thresholds. The regular one kicks in when 20% of the table has been changed (by default). The analyzing task starts when 10% of the table is modified. Let’s see that in action.
Let’s start by creating a test table:
CREATE TABLE test(id int)
We can now check when it’s been vacuumed:
SELECT last_vacuum, last_autovacuum
FROM pg_stat_all_tables
WHERE schemaname = 'public' AND relname = 'test';
It should return the following:
last_vacuum last_autovacuum
(null) (null)
We can now insert many rows and see that the table hasn’t been vacuumed either:
INSERT INTO test SELECT * FROM generate_series(1,1000)
SELECT last_vacuum, last_autovacuum
FROM pg_stat_all_tables
WHERE schemaname = 'public' AND relname = 'test';
last_vacuum last_autovacuum
(null) (null)
We can now update the table:
UPDATE test SET id = -id WHERE id < 500
And this time, the autovacuum should kick in as we modified nearly 50% of the table:
SELECT last_vacuum, last_autovacuum
FROM pg_stat_all_tables
WHERE schemaname = 'public' AND relname = 'test';
last_vacuum last_autovacuum
(null) "2024-09-11 15:22:38"
We can also vacuum the table manually:
VACUUM public.test
We should now see the following:
SELECT last_vacuum, last_autovacuum
FROM pg_stat_all_tables
WHERE schemaname = 'public' AND relname = 'test';
last_vacuum last_autovacuum
"2024-09-11 15:24:09" "2024-09-11 15:22:38"
Finetuning
We can adjust many parameters to configure how often the vacuuming runs.
autovacuum: Controls whether the autovacuum background process is enabled or disabled. By default, this feature is turned on.
autovacuum_vacuum_threshold: Specifies the minimum number of dead rows that must accumulate in a table before the vacuum process is triggered. The default setting is 50.
Autovacuum_analyze_threshold: Defines the minimum number of live rows that need to exist in a table before the analyze process is initiated. The default value is 50.
autovacuum_vacuum_scale_factor: A multiplier that adjusts the number of dead rows required to trigger a vacuum, based on the table's size. The default multiplier is 0.2.
autovacuum_analyze_scale_factor: A multiplier that determines how many live rows are necessary to trigger an analyze, relative to the table's size. The default value is 0.1.
autovacuum_vacuum_cost_delay: Specifies the delay (in milliseconds) before the autovacuum process begins a vacuum operation. The default delay is 20 milliseconds.
autovacuum_vacuum_cost_limit: Sets the maximum number of rows that can be processed during a single vacuum operation. The default limit is 200.
We can also follow some best practices:
Don’t run manual VACUUM without a reason - manual vacuum may collide with other activities and cause I/O and CPU spikes
If running a VACUUM manually, run it on a table-by-table basis. Do it outside of peak hours.
Run VACUUM ANALYZE when the distribution of the values changes significantly.
Run VACUUM ANALYZE after bulk-loading many rows.
Avoid VACUUM FULL. Run it only when performance degrades significantly.
Adjust vacuuming thresholds based on your specific needs.
Postgres should do quite well without any intervention, so you can rely on your defaults.
Summary
Vacuuming in PostgreSQL is important because it helps manage dead rows left behind after updates or deletes, preventing table bloat and reclaiming storage space. It also maintains the efficiency of query performance by updating table statistics for the query planner and preventing transaction ID wraparound, which can lead to database corruption if not addressed. Regular vacuuming ensures the database remains optimized and functions smoothly.







