This cycle is repeated whenever we want to upgrade or update the service and have a day 0 to 1 to 2 process for the new features.
If we were buying a car then Day 0 would be everything from the moment we decided we wanted a new car through comparing models, arguing with sales representatives, getting financing for the car and finally walking out the door with the keys.
Day 1 in this metaphor would be the first few days of ownership, when we’re still figuring out which side of the car we put in fuel, how to set the radio for our favourite stations, and get to know how the engine sounds at different speeds. Day 1 can take a few hours or a few weeks, depending on how all sorts of things such as how different the new car is or how experienced we are as drivers.
Day 2 is, of course, our day-to-day usage of the car. Everything from traveling from point A to point B, filling up the car with fuel, cleaning the car, fixing flat tires, and dealing with other drivers on the road.
For the James Webb Space Telescope, Day-0 started back in 1995 when the initial planning for Hubble’s next generation successor began and continued for over 25 years of design, re-design, construction, testing, failures, re-re-design, re-construction, re-testing, successes, integration of all the pieces, sending to French Guinea, launching in December 2021, unfolding in deep space, arriving at a special spot in space called L2 and cooling down to the right temperature.
About six weeks after launch, Webb had finally completed its initial deployment and was ready for its engineering and scientific calibration, or day 1 work.
At the highest level of abstraction, three things happen during this time period, all of which have immediate parallels to the Day-1 work SREs do when a new service is deployed.









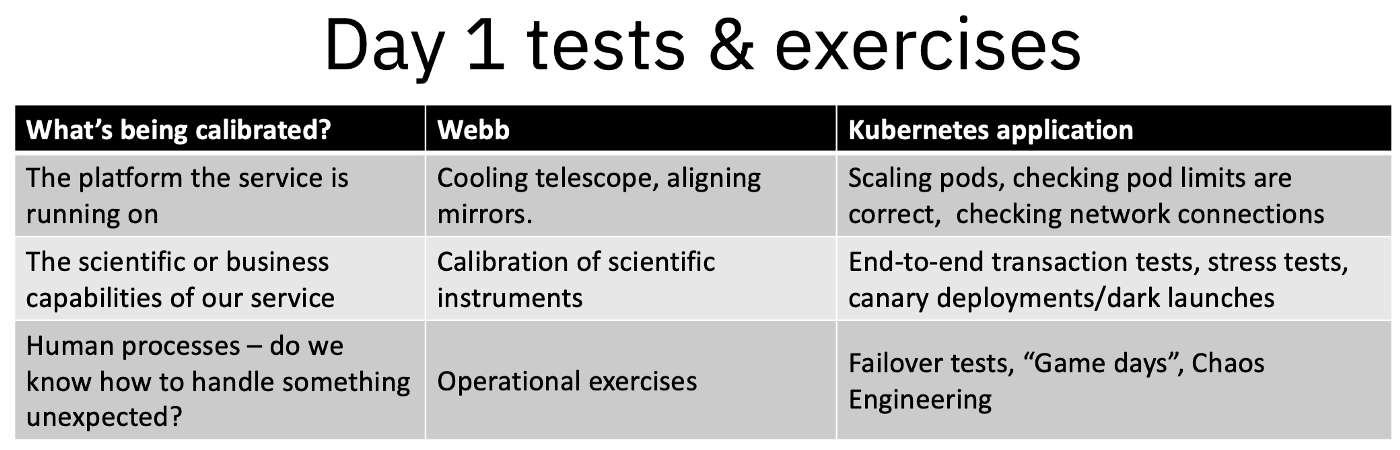


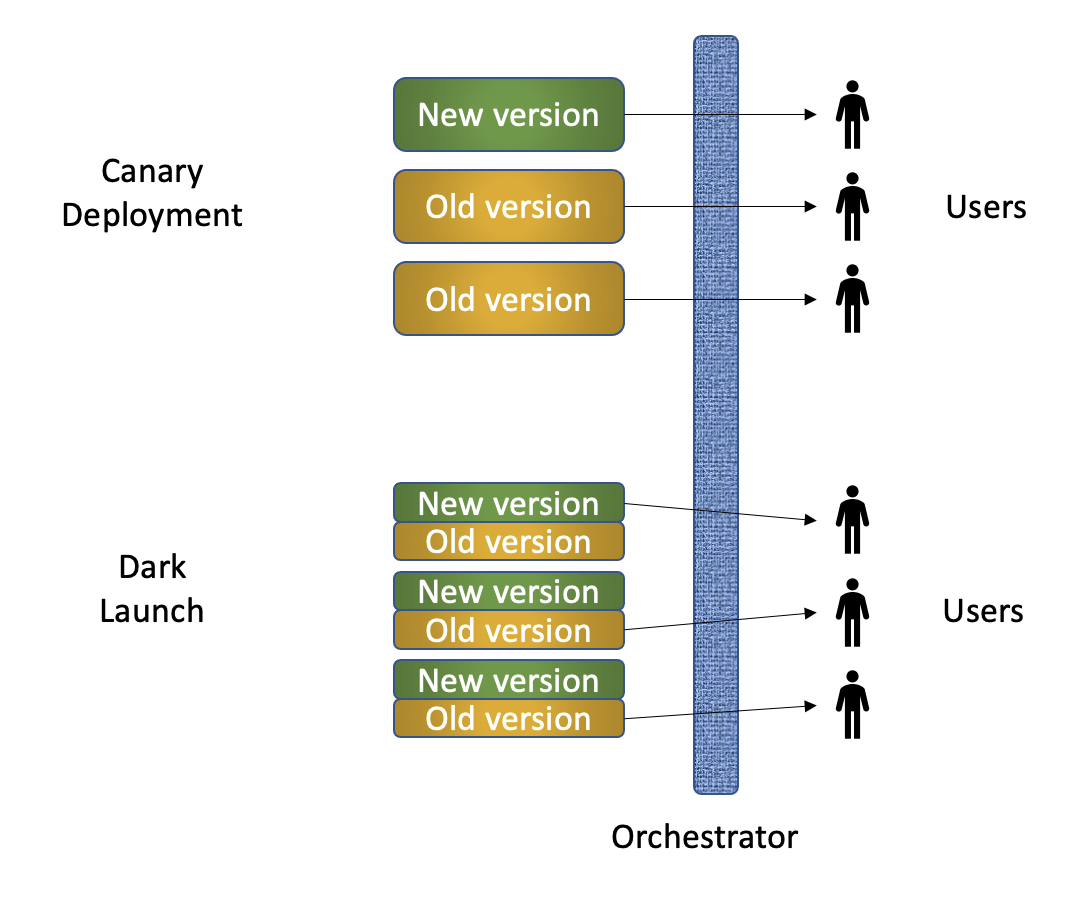







#/media/File:Hubble_First_Light,_First_Released_Image_(STScI-1990-04a).png){kind=link}