






Modern software delivery pipelines are expected to move quickly. Engineering teams deploy continuously, merge code frequently, and rely heavily on automated validation to maintain release confidence. In many organizations, deployment speed has become a competitive advantage.
But as release frequency increases, another challenge becomes harder to ignore: balancing regression coverage with pipeline efficiency.
Most teams want broader validation coverage. They want to catch regressions earlier, reduce production failures, and improve deployment reliability. At the same time, they also want pipelines that execute quickly enough to support continuous delivery.
This creates one of the most important operational trade-offs surrounding modern regression testing tools: improving coverage without slowing software delivery to the point where pipelines become inefficient.
The problem is not simply technical. It affects developer productivity, deployment confidence, debugging workflows, and overall engineering velocity.
Why Regression Suites Keep Growing
Regression testing naturally expands as applications evolve.
Over time, teams add tests for:
- New features
- Bug fixes
- API behavior
- Authentication workflows
- Service integrations
- Edge-case scenarios
Initially, this feels beneficial because broader coverage improves release confidence.
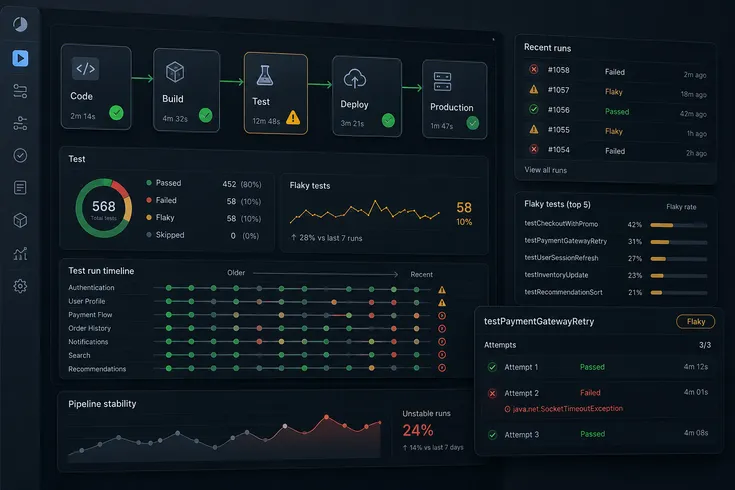
But as systems scale, regression suites often become increasingly difficult to manage.
Pipelines that once completed in minutes begin taking much longer. Test execution becomes more resource-intensive. Developers wait longer for feedback. Deployment workflows slow down.
The trade-off becomes unavoidable.
Why Coverage Alone Is Not Enough
Many engineering teams assume that increasing test coverage automatically improves software quality.
In reality, large regression suites do not always produce better validation.
Some teams eventually face problems such as:
- Duplicate test coverage
- Low-value assertions
- Brittle end-to-end workflows
- Flaky integration tests
- Outdated scenarios that no longer reflect production behavior
At that stage, adding more tests can reduce pipeline reliability instead of improving it.
The issue is not the number of tests. It is the quality, relevance, and operational efficiency of the validation strategy itself.
How Pipeline Speed Affects Engineering Productivity
Slow pipelines create friction across the entire development lifecycle.
When regression testing takes too long:
- Pull request feedback slows down
- Developers lose context while waiting for results
- Deployment frequency decreases
- Hotfixes take longer to release
- Teams rerun jobs repeatedly to investigate failures
Over time, slow validation can discourage engineers from relying on the pipeline itself. This becomes especially problematic in continuous delivery environments where fast feedback loops are essential for maintaining development velocity.
Why Distributed Systems Make the Problem Worse
Modern software systems rarely operate as isolated applications.
Most engineering environments now involve:
- Microservices architectures
- API-driven communication
- Shared infrastructure dependencies
- Event-driven workflows
- Independently deployed services
Each additional dependency increases the complexity of regression validation.
A single workflow may now involve multiple services interacting asynchronously across distributed infrastructure.
To improve confidence, teams often add more integration and end-to-end tests. But these tests are usually slower and harder to maintain than isolated unit tests.
As a result, pipelines become heavier over time.
The False Choice Between Speed and Stability
Many organizations eventually treat pipeline speed and regression coverage as opposing goals.
They either:
- Reduce testing aggressively to accelerate releases
or - Increase validation so heavily that delivery pipelines slow significantly
Neither approach works well long term.
Reducing coverage increases production risk. Overloading pipelines reduces delivery efficiency.
Modern regression testing strategies increasingly focus on optimizing validation quality instead of maximizing raw test volume.
How Modern Regression Testing Tools Address This Trade-Off
Modern regression testing tools are evolving to help engineering teams manage this balance more effectively.
Rather than simply running every test for every deployment, newer approaches focus on improving the relevance and efficiency of validation workflows.
This shift includes several important changes.
1. Prioritizing High-Risk Workflows
Not every workflow carries the same operational risk.
Modern regression strategies increasingly prioritize:
- Core business functionality
- Frequently modified services
- Critical API interactions
- High-impact user journeys
This allows pipelines to focus validation resources where failures would matter most.
2. Smarter Test Selection in CI/CD Pipelines
Running the entire regression suite for every code change is often inefficient.
Many teams now use selective execution strategies that validate:
- Affected services
- Related dependencies
- Connected workflows
- Recently modified components
This reduces unnecessary execution time while preserving meaningful coverage.
3. Improving Test Reliability Instead of Increasing Quantity
Large unstable suites create operational noise.
Flaky tests often produce more pipeline disruption than real regressions.
Modern testing workflows increasingly emphasize:
- Deterministic validation
- Stable environment handling
- Better synchronization logic
- Reduced dependency on timing-sensitive behavior
Reliable tests improve pipeline trust far more effectively than simply adding additional coverage.
4. Moving Toward Production-Aware Validation
One reason large regression suites become inefficient is that many tests validate unrealistic scenarios.
Modern regression testing approaches increasingly focus on validating:
- Real application interactions
- Production-like traffic patterns
- Actual service communication behavior
- Realistic data conditions
This allows teams to improve regression signal quality without relying solely on larger test volumes.
Platforms like Keploy are often discussed in this context because they support production-aware API regression workflows that help engineering teams generate meaningful automated validation from real application behavior rather than depending entirely on manually authored test cases.
This reflects a broader shift in how modern regression testing tools are evolving.
Why Feedback Quality Matters More Than Raw Coverage
Fast pipelines alone are not useful if validation signals are unreliable.
Similarly, massive regression coverage provides little value if developers stop trusting pipeline results.
The most effective CI/CD systems optimize for feedback quality.
High-quality validation provides:
- Fast and reliable failure detection
- Clear debugging signals
- Stable deployment confidence
- Operationally meaningful regression coverage
This balance matters more than maximizing any single metric.
The Operational Cost of Over-Testing
Excessive regression validation creates hidden operational costs that teams often underestimate.
These include:
- Increased infrastructure usage
- Slower release cycles
- More pipeline maintenance work
- Higher debugging overhead
- Reduced developer productivity
In large engineering organizations, inefficient validation workflows can affect delivery performance significantly.
Why Modern Teams Are Re-Evaluating Regression Strategy
Engineering teams are increasingly recognizing that testing effectiveness depends less on test volume and more on strategic validation design.
Modern regression workflows increasingly prioritize:
- Faster feedback loops
- Realistic system behavior
- Selective execution models
- Production-aware validation
- Stable automated testing environments
This shift helps teams maintain release confidence while preserving CI/CD efficiency.
Conclusion
The trade-off between regression coverage and pipeline speed has become one of the defining operational challenges in modern software delivery.
As systems become more distributed and deployment frequency increases, simply expanding regression suites is no longer a sustainable solution.
Modern regression testing tools are evolving beyond raw coverage expansion toward smarter, more production-aware validation strategies that improve signal quality while preserving pipeline efficiency.
For engineering teams operating fast CI/CD systems, the goal is no longer maximum testing. It is reliable, meaningful, and operationally efficient validation that supports both speed and stability simultaneously.






