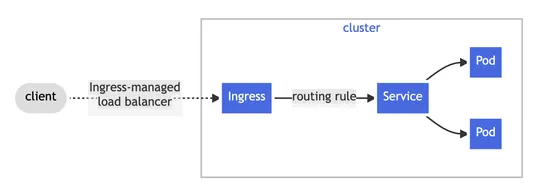
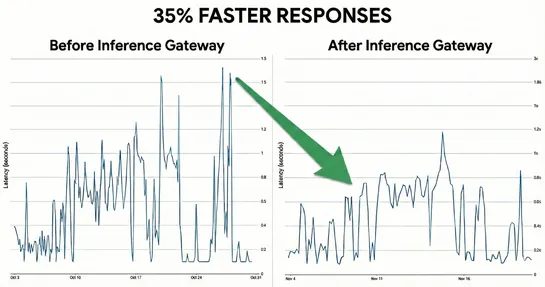
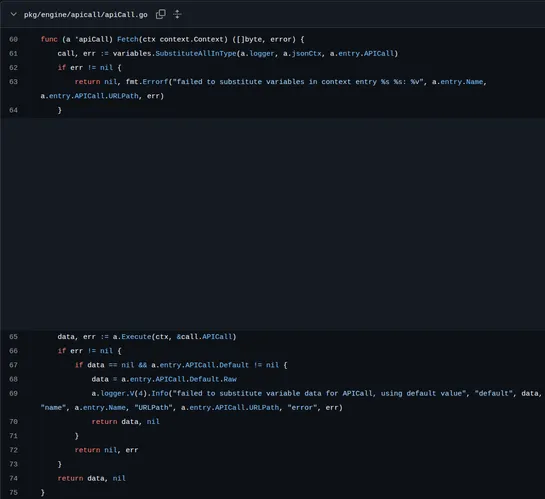
What Is an Async Agent, Really?
An async agent is not inherently async, it depends on whether you wait for it to finish or not. Async agents can manage their own event loop of other agents, spawning and coordinating them to handle tasks, just like an async runtime in programming. This architectural distinction allows for concurren.. read more