OpenMetrics vs OpenTelemetry: A Detailed Comparison
Discover the key differences between OpenMetrics and OpenTelemetry, from scope and use cases to adoption and flexibility, to make an informed choice.
Join us

Discover the key differences between OpenMetrics and OpenTelemetry, from scope and use cases to adoption and flexibility, to make an informed choice.

Learn about the 5 common incident severity levels and how they impact your response to system issues, ensuring faster resolutions.

Syslog levels help categorize log messages by severity, making it easier to monitor, troubleshoot, and prioritize system events.

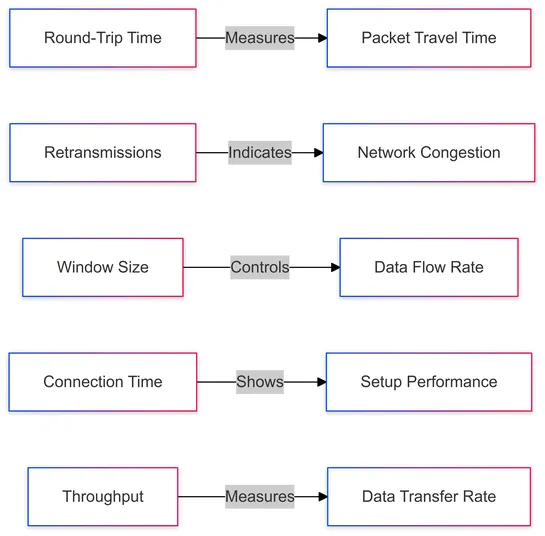
Learn how TCP monitoring keeps your network fast, reliable, and free from issues like latency, packet loss, and connection hiccups.
Learn about IoT monitoring, its benefits, best practices, and use cases to optimize your systems and improve operational efficiency.

Error logs are vital for troubleshooting, improving performance, and ensuring security. Learn how to use them effectively for system health.


In this article, we’ll explore what an epic is, why using an epic template can help organize complex projects, and how tools like Smart Templates for Jira can further improve your workflows by enabling reusable templates for entire epics.
If you’re curious about Datadog pricing, we’ve got answers to your top questions, from plans to smart ways to save on costs.

Learn the key differences between git fetch and git pull, and understand when to use each command for better control over your workflow.

Master Git with this cheat sheet! Learn essential and advanced commands to simplify your workflow and fix mistakes.


