How to Integrate OpenTelemetry with Django
Learn how to integrate OpenTelemetry with Django to monitor performance, trace requests, and improve observability in your applications.
Join us

Learn how to integrate OpenTelemetry with Django to monitor performance, trace requests, and improve observability in your applications.

Ensure your app's reliability with best practices in monitoring: choose key metrics, configure alerts, and stay proactive for optimal performance.

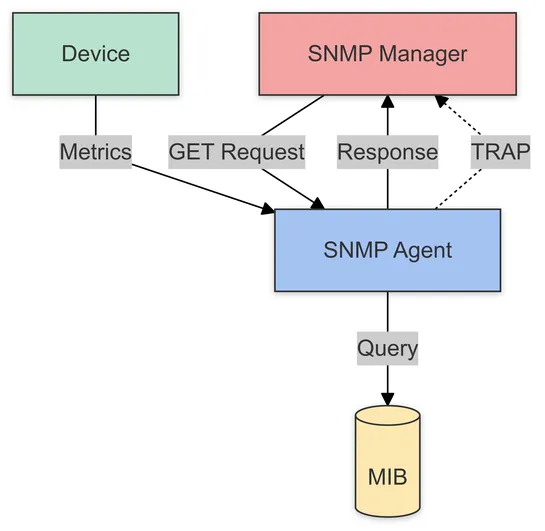
SNMP monitoring is crucial for tracking network device performance, helping optimize and secure your network with real-time insights.
Learn how to integrate gRPC with OpenTelemetry for better observability, performance, and reliability in microservices architectures.
Learn how to configure and manage Linux Syslog for better system monitoring, troubleshooting, and log management with these helpful tips.

Learn the best practices and techniques for efficient Spring Boot logging to enhance performance, security, and troubleshooting in your applications.

Explore the essential components, types, and best practices for managing application logs to optimize troubleshooting, performance, and security.

Parquet outperforms CSV with its columnar format, offering better compression, faster queries, and more efficient storage for large datasets.

Get the hang of npm with this handy cheatsheet—listing packages, installing, troubleshooting, and tips to make your dev life easier!

Discover the top 7 AWS alternatives, comparing features, benefits, and what makes each one a strong cloud solution for your needs.


