LLMs Are Good at SQL. We Gave Ours Terabytes of CI Logs.
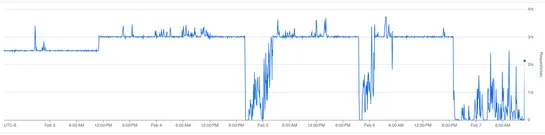
Mendral's agent runs ad‑hocSQLagainst compressedClickHouselogs. It traces flaky tests across months and scans up to 4.3B rows per investigation. They denormalize 48 metadata columns per log line. They compress 5.31 TiB down to ~154 GiB (~21 bytes/line) — a 35:1 ratio. That turns arbitrary filters in.. read more