What Are AI Guardrails
Learn the core concepts of AI guardrails and how they create safer, more reliable, and well-structured AI systems in production.
Join us

Learn the core concepts of AI guardrails and how they create safer, more reliable, and well-structured AI systems in production.

On October 20, 2025, AWS suffered a major disruption in its US-EAST-1 region, impacting over 140 services including EC2, Lambda, S3, and DynamoDB. The root cause? A DNS resolution failure that cascaded through dependent systems — showing how even the strongest cloud infrastructures can falter. At RE..

Our latest quick guide shows you how to spin up the RELIANOID Enterprise Edition on AWS in just a few commands — using the official Terraform module from the Terraform Registry. You’ll automatically provision: ✅ VPC + Internet Gateway ✅ Public Subnet ✅ Security Group (SSH 22, Web GUI 444) ✅ EC2 Inst..
A practical guide to setting up Grafana Tempo, configuring key components, and understanding how to use tracing across your services.

Just after Japan’s new Active Cyberdefence Law (ACD Law) came into effect — a major step toward reshaping the country’s cybersecurity posture — Japan’s largest brewer, Asahi Group, has suffered a ransomware attack that disrupted production and logistics nationwide. ⚠️ This incident starkly illustrat..


A developer rolled outMagicbrake- a no-fuss GUI forHandbrakeaimed at folks who don’t speak command line. One button. Drag, drop, convert. Done. It strips Handbrake down to the bones for anyone who just wants their video in a different format without decoding flags and presets... read more
Netflix gutted Tudum’s old read path—Kafka, Cassandra, layers of cache—and swapped inRAW Hollow, a compressed, distributed, in-memory object store baked right into each microservice. Result? Homepage renders dropped from 1.4s to 0.4s. Editors get near-instant previews. No more read caches. No extern.. read more

uvis a new Rust-powered CLI from Astral that tosses Python versioning, virtualenvs, and dependency syncing into one blisteringly fast tool. It handles yourpyproject.tomllike a grown-up—auto-generates it, updates it, keeps your environments identical across machines. Need to run a tool once without t.. read more

A sneaky bug inPyTorch’s MPS backendlet non-contiguous tensors silently ignore in-place ops likeaddcmul_. That’s optimizer-breaking stuff. The culprit? ThePlaceholder abstraction- meant to handle temp buffers under the hood - forgot to actually write results back to the original tensor... read more
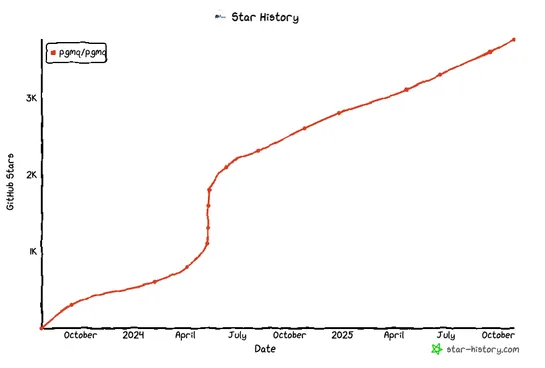
Postgres is pulling Kafka moves—without the Kafka. On a humble 3-node cluster, it held 5MB/s ingest and 25MB/s egress like a champ. Low latency. Rock-solid durability. Crank things up, andsingle-node Postgresflexed hard: 240 MiB/s in, 1.16 GiB/s out for pub/sub. Thousands of messages per second in q.. read more