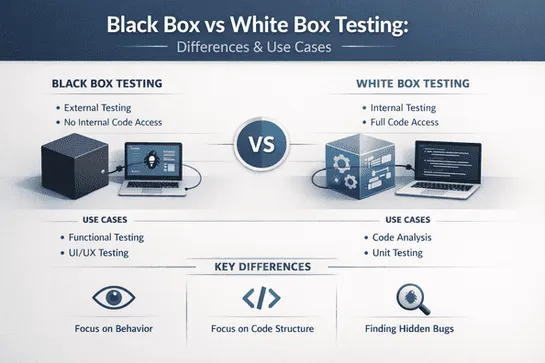
Black Box vs White Box Testing in Unit, Integration & E2E Testing: Where Each Belongs
Understand where black box and white box testing belong across unit, integration, and E2E testing. Learn the right technique for every layer of your test suite.
Join us

Understand where black box and white box testing belong across unit, integration, and E2E testing. Learn the right technique for every layer of your test suite.
⚡ Deploy RELIANOID Load Balancer Community Edition v7 on AWS in minutes with Terraform. From zero to a fully functional load balancer — automated, reproducible, and ready to go. 👉 Follow the step-by-step guide and get started fast. #Terraform#AWS#InfrastructureAsCode#DevOps#RELIANOID#Automation http..
🔐 𝗨𝗻𝗱𝗲𝗿𝘀𝘁𝗮𝗻𝗱𝗶𝗻𝗴 𝘁𝗵𝗲 𝗨𝗞 𝗣𝗦𝗧𝗜 𝗔𝗰𝘁: 𝗔 𝗡𝗲𝘄 𝗘𝗿𝗮 𝗳𝗼𝗿 𝗖𝗼𝗻𝗻𝗲𝗰𝘁𝗲𝗱 𝗗𝗲𝘃𝗶𝗰𝗲 𝗦𝗲𝗰𝘂𝗿𝗶𝘁𝘆 The UK is raising the bar on cybersecurity with the Product Security and Telecommunications Infrastructure (PSTI) Act, now in force since April 2024. As cyber threats continue to grow, this regulation introduces a baseline for ..


The author experimented with storing data in a Logitech mouse's flash memory. Logitech mice communicate through HID++, a protocol that maps device features using stable IDs. Despite efforts to write data to certain registers, only the DPI register could retain data across power cycles... read more
A former Azure Core engineer recounts arriving on his first day to find a 122-person org seriously planning to port Windows-based VM management agents - 173 of them, which nobody could fully explain - onto a tiny, low-power ARM chip running Linux. The stack was already failing to scale on server-gra.. read more

The essay discusses the misconceptions around companies that burn a lot of money, drawing comparisons to Amazon's successful strategy. It delves into examples like Uber and WeWork to highlight the importance of understanding the long-term implications of cash burn. The focus is on the strategies and.. read more
In the wake of AI coding assistants like Claude and Codex, many wonder if the human role of "computer programmer" is ending. Although AI shows promise, human developers are valuable in the current transitional period. Real programmers are uniquely positioned to harness AI's power while augmenting it.. read more



