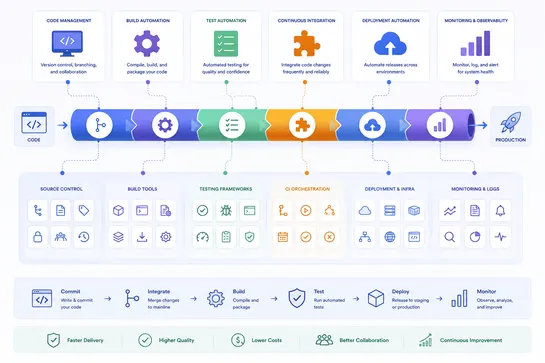
𝗼𝗽𝗲𝗿𝗮𝘁𝗶𝗼𝗻𝗮𝗹 𝗿𝗲𝘀𝗶𝗹𝗶𝗲𝗻𝗰𝗲 𝗮𝗻𝗱 𝘁𝗵𝗲 𝘁𝗿𝘂𝗲 𝗰𝗼𝘀𝘁 𝗼𝗳 𝗱𝗼𝘄𝗻𝘁𝗶𝗺𝗲
🎉 We're honored to be featured in this excellent article on one of today's most important topics: 𝗼𝗽𝗲𝗿𝗮𝘁𝗶𝗼𝗻𝗮𝗹 𝗿𝗲𝘀𝗶𝗹𝗶𝗲𝗻𝗰𝗲 𝗮𝗻𝗱 𝘁𝗵𝗲 𝘁𝗿𝘂𝗲 𝗰𝗼𝘀𝘁 𝗼𝗳 𝗱𝗼𝘄𝗻𝘁𝗶𝗺𝗲. It's always rewarding to see industry experts recognize the critical role that intelligent application delivery, high availability, and resilient tr..