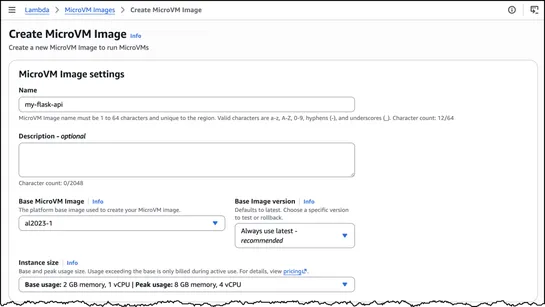
Why your microVM sandbox solves a particular problem very well, but not the agent security problem.
Use MicroVMs to contain host-escape risk from coding agents. You still need capability controls: grant the agent access to specific files, scoped credentials, approved services, and permitted mutations after you place repos and credentials inside the VM... read more