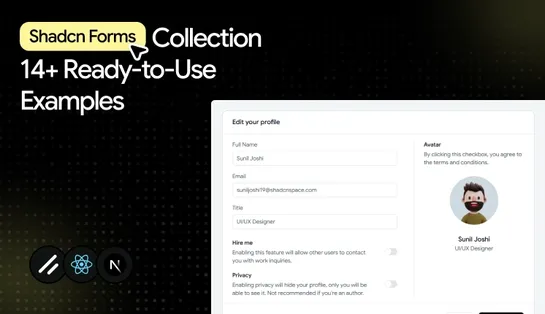
14+ Shadcn Form Templates Every React Developer Should Bookmark
Every Shadcn UI form below was evaluated on accessibility support, validation handling, and how well it holds up inside admin dashboards, SaaS platforms, internal tools, and business applications.
Below are 14 Shadcn form templates and examples worth keeping in your shadcn resources.