







Kubernetes is an open source container orchestration platform for scheduling and automating the deployment, management and scaling of containerized applications. Containers operate in a multiple container architecture called a “cluster.” A Kubernetes cluster includes a container designated as a “master node” that schedules workloads for the rest of the containers — or “worker nodes” — in the cluster.
The master node determines where to host applications (or Docker containers), decides how to put them together and manages their orchestration. By grouping containers that make up an application into clusters, Kubernetes facilitates service discovery and enables management of high volumes of containers throughout their lifecycles.
Google introduced Kubernetes as an open source project in 2014. Now, it’s managed by an open source software foundation called the Cloud Native Computing Foundation. Designed for container orchestration in production environments, Kubernetes is popular due in part to its robust functionality, an active open source community with thousands of contributors and support and portability across leading public cloud providers (e.g., IBM Cloud, Google, Azure and AWS).
Each Kubernetes cluster has multiple components:
- Master
- Nodes
- Kubernetes objects (namespace, pods, containers, volumes, deployment, Service, etc)
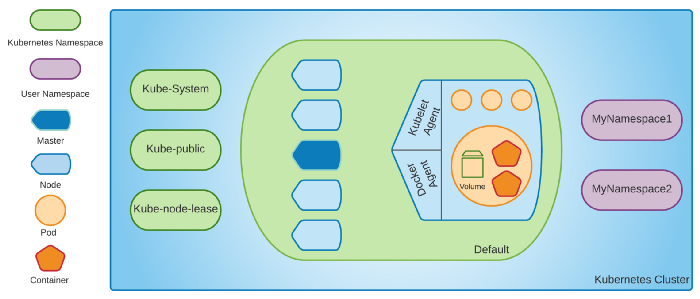
What is a namespace in the Kubernetes cluster?
It is a cluster inside a Kubernetes cluster. It provides logical segregation of the applications from different teams/for different purposes. We create a namespace for each team and restrict their access to the assigned namespace only so that none of the team can access other team’s namespace or interfere with other’s containers and resources.
Each Kubernetes cluster comes with 4 default namespaces:
- Kube-system: We don’t modify and create anything in this namespace. It has processes like master process, kubectl process, system process, etc.
- Kube-public: It has public accessible data like configMap. Try this command to get cluster-info
kubectl cluster-info - Kube-node-lease: It is used to read the heartbeats of the nodes to determine the availability of the nodes in the cluster.
- Default: It is the namespace used by us to create resources. We can create our own namespace if multiple teams are utilizing the same cluster.
We can also use a namespace using a configuration file which is a recommended way to create a namespace.
What is kubectl?
The kubectl command-line tool lets you control Kubernetes clusters.
command: Specifies the operation that you want to perform on one or more resources, for examplecreate,get,describe,delete.TYPE: Specifies the resource type. Resource types are case-insensitive and you can specify the singular, plural, or abbreviated forms.NAME: Specifies the name of the resource. Names are case-sensitive. If the name is omitted, details for all resources are displayed, for examplekubectl get pods.flags: Specifies optional flags. For example, you can use the-sor--serverflags to specify the address and port of the Kubernetes API server.
Kubernetes architecture
Looking inside Kubernetes from the architecture point of view we can see two main parts: control plane and worker nodes.
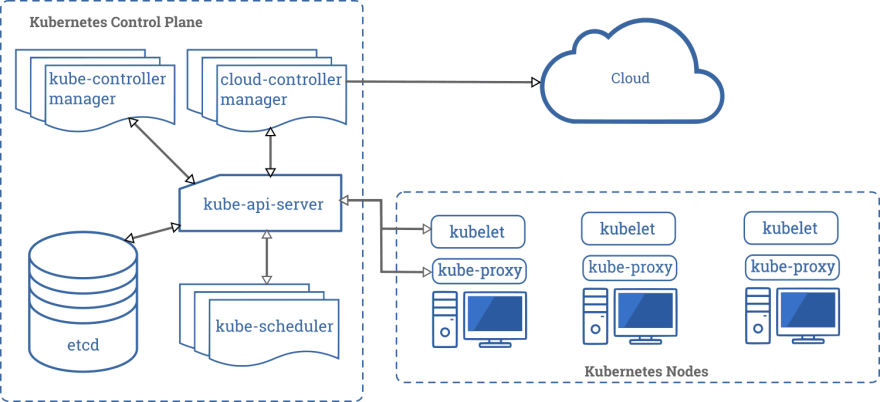
Source: kubernetes.io
First one is responsible for managing the entire cluster and latter are responsible for hosting applications (containers).
Control plane decides on which worker node run each container, checks health state of a cluster, provides an API to communicate with cluster and many more. If one of the nodes will go down and if some containers were running on that broken machine, it* *will take care of rerunning those applications on other nodes.
Inside control plane we can find several, smaller components:
- kube-api-server — it’s responsible for providing an API to a cluster, it provides endpoints, validates requests and delegates them to other components,
- kube-scheduler — constantly checks if there are new applications (Pods, to be specific, the smallest objects in K8s, representing applications) and assign them to nodes,
- kube-controller-manager — contains a bunch of controllers, which are watching a state of a cluster, checking if a desire state is the same as current state and if not they communicate with kube-api-server to change it; this process is called control loop and it concerns several Kubernetes objects (like nodes, Pod replicas and many more); for each K8s object there is one controller which manages its lifecycle,
- etcd — it’s a reliable key-value store database, which stores configuration data for the entire cluster,
- cloud controller manager — holds controllers that are specific for a cloud providers, it’s available only when you use at least one cloud service in a cluster.
Also another component, that is not mentioned on a above picture, but is very important, is DNS. It enables applications inside the cluster to be able to communicate with each by specific (human-readable) names, and not IP addresses.
Apart from the control plane each Kubernetes cluster *can have one or more *workorder nodes on which application are running. To integrate them with K8s each one of them has:
- kubelet — is responsible of managing Pods inside the node and communicating with control plane (both components talk with each other when a state of a cluster needs to be changed),
- kube-proxy — take care of networking inside a cluster, make specific rules etc.
Kubernetes Objects
In the previous section I’ve mentioned something called Kubernetes Object, so let’s quickly look on what are they.
As mentioned before K8s provides an abstraction of an infrastructure. And to interact with a cluster we need to use some kind of the interface that will represent a state of it. And these are the Kubernetes objects, all of them represent a state of entire system. They are usually defined as a YAML files so that they can be saved under version control system and has an entire system declaratively described, which is very close to Infrastructure as Code approach.
There are several types of objects, but I want to mention only couple of them, which are the most important:
- Pods — as mentioned before, Pods are the smallest Kubernetes objects that represents an application. What is worth mentioning, Pods are not containers. They’re wrapper for one or more containers, which contains not only working application but also some metadata.
- Deployments — are responsible for a life cycle of Pods. They take care of creating Pods, upgrading and scaling them.
- Services — take care of networking tasks, communication between Pods inside a cluster. The reason for that is because Pod’s life is very short. They can be created and killed in a very short time. And every time the IP address can change so other Pods inside cluster would need to constantly update addresses of all depended applications (service discovery). Moreover there could be a case that are more than one instances of the same application inside the cluster — Services take care of load balancing a traffic between those Pods.
- Ingress — similar to Services, Ingress is responsible for networking, but on a different level. It’s a gateway to a cluster so that someone/something from external world can enter it based on rules defined in Ingress Controller.
- Persistent Volumes — provide an abstract way for data storage, which could be required by Pods (e.g. to save some data permanently or in cache).
- ConfigMaps — they holds key-value data that can be injected to Pods, for example as a environment variable, which allows to decouple an application from its configuration.
Apart from standard types of objects Kubernetes offer to create own Custom Resources, which allows to create either new versions of existing objects (with different behaviour) or brand new resource which will cover different aspect. They are widely used in something called Operator pattern and example of such would be a database operator which periodically do backups of databases (more examples of operators can be found on OperatorHub.io). With operators you can easily customize infrastructure to your needs and building the entire ecosystem on top of the Kubernetes.
Features of Kubernetes
I hope that now you understand a primary problem that Kubernetes is trying to solve. But this is not everything, there are more aspects of software engineering that it is addressing.
Scalability
One of the most important features of Kubernetes, that was already partially mentioned, is that it allows to scale number of application instances based on CPU usage (horizontal auto-scaling).
This is one of the cloud fundamental concept that depending on how busy an application is (how much of CPU it requires) K8s could decide to run additional instances of the same Pod to prevent low latencies or even crushes.

For example, e-commerce application in summer has rather a low user traffic. Customers prefer spending vacation in great places rather than buying new things. But during the year there are periods (like Black Friday, time before Christmas) when a number of customers using application dramatically increase, which requires more resources on a server side.
In traditional approach to prevent it from happening e-commerce company would need to have a big, expensive server which would be able to handle such peak of a traffic, but for most of the time during a year those resource would not be used (and generate loses for a company).
This is why cloud computing, with Kubernetes, is so popular today. It scales a number of application instances depending on their busyness. You pay to a provider only for how much resources (CPU, RAM, memory) does your application actually require.
High Availability
When big companies are running their application they want to do that in reliable way. It means that they won’t accept a situation that even for a minute an application could be not working, because they might lose customers and therefore money.
But in real life many bad things could happen. For example, one or more servers (nodes) could went down. Or maybe one or more microservices could went down for whatever reasons. As developers and infrastructure specialists we should make sure that it never happens, but it’s a vain hope.
Luckily Kubernetes has a mechanism to cope with such situation. For example, if an application (Pod) crushes it will try to automatically recreate it. Or if a node go down it will automatically assign all Pods that are running on a crushed node to a new one.

Monitoring & Observability
As it was mentioned before Kubernetes has an ability to autoscale number of application instances based on CPU usage. It collects metrics from every application about resources usage through the Metrics API, so that it can decide when to increase/decrease number of Pods. Also it can provide current consumption information on a dashboard.
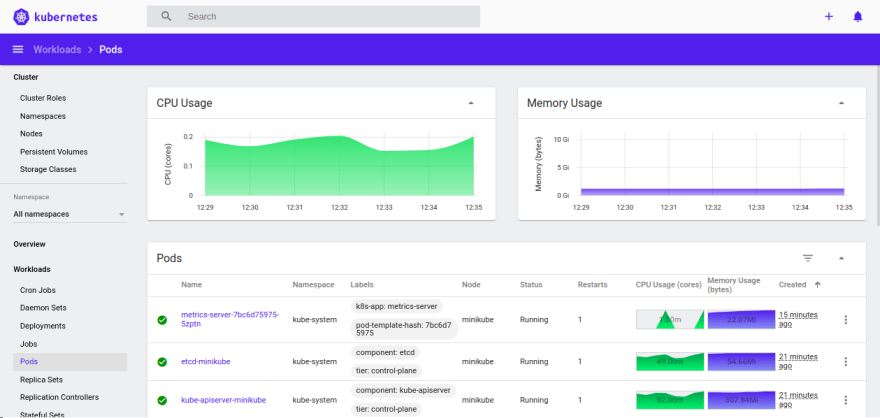
Mini-kube dashboard for CPU and Memory usage for entire cluster
By default Kubernetes provides Metrics Server for providing such metrics, but it can be replaced by custom one. The most popular one is Prometheus.
Another problem of distributed systems is that it is really hard to track full process flow between several applications. In monolithic apps it’s quite simple, there is a one place where process logs could be checked, but in microservice approach you would need to check each application individually.
Therefore, in Kubernetes there are three basic concepts that every application should provide to achieve observability and have full insight about them to a cluster:
- metrics — they give information a health status (partially mentioned at the beginning of this section),
- logs — represent a descriptive event (usually in full text) inside application written into standard output; all logs from every application can be aggregated to a single place using e.g. Elastic Stack — Elasticsearch, Kibana, Beats and Logstash,
- traces — allows to combine multiple events/operations across multiple components, so single trace represents all communication between all components (databases, HTTP requests, etc.); popular tool used for tracing is Jaeger.
Advantages and Drawbacks of Kubernetes
Take a look at the main advantages and disadvantages of Kubernetes.
Advantages:
- Simplifies rolling updates, canary deployments, horizontal autoscaling, and other deployment operations.
- Automated processes help speed up delivery and improve general productivity.
- Its ability to run across multiple environments eliminates infrastructure lock-ins.
- Provides the foundation for working with cloud-native apps.
- Its features support high availability, low downtime, and overall more stable applications.
Disadvantages:
- The complexity of the platform is not efficient for smaller applications.
- Migrating a non-containerized application onto the Kubernetes platform could be quite challenging.
- Due to its complexity, there is a steep learning curve that may initially reduce productivity.
Different types of deployment
One of the biggest challenge in software world is to ship a new version of an application in reliable way. It’s usually a problem of how to quickly roll out new version of it (and if necessary, quickly roll back) and making it almost invisible for the end user.
Some companies are releasing their apps overnight during the weekend. Usually they warn users that for couple hours it won’t be available, so that they are able to do full upgrade. For some use cases this approach is totally fine, but for applications that are served all other the world for a full day, that might be tricky.
In Kubernetes it’s very easy to overcome it by achieving Zero Downtime Deployment. And it’s done by following blue/green deployment pattern .
The concept is quite simple. When we want to release a new version of an app, inside a cluster we deploy a new version alongside with an old one, but at first without routing any traffic to a new instance. Only after making sure that it didn’t break anything user traffic can be routed to a new version.

But there is more. K8s allows to have more complex types of deployments, such as canary deployment or A/B testing. In both of them two versions of a service are deployed alongside.
In a first one traffic is routed only to a very small percentage of a users and then it’s steadily increased if there are no problems.
In A/B testing we want to have two different version of application for a whole time so that we can compare which one performs better (has bigger user traffic, in which one users spend more money, etc.).
Why you need Kubernetes and what it can do
Containers are a good way to bundle and run your applications. In a production environment, you need to manage the containers that run the applications and ensure that there is no downtime. For example, if a container goes down, another container needs to start. Wouldn’t it be easier if this behavior was handled by a system?
That’s how Kubernetes comes to the rescue! Kubernetes provides you with a framework to run distributed systems resiliently. It takes care of scaling and failover for your application, provides deployment patterns, and more. For example, Kubernetes can easily manage a canary deployment for your system.
Kubernetes provides you with:
- Service discovery and load balancing Kubernetes can expose a container using the DNS name or using their own IP address. If traffic to a container is high, Kubernetes is able to load balance and distribute the network traffic so that the deployment is stable.
- Storage orchestration Kubernetes allows you to automatically mount a storage system of your choice, such as local storages, public cloud providers, and more.
- Automated rollouts and rollbacks You can describe the desired state for your deployed containers using Kubernetes, and it can change the actual state to the desired state at a controlled rate. For example, you can automate Kubernetes to create new containers for your deployment, remove existing containers and adopt all their resources to the new container.
- Automatic bin packing You provide Kubernetes with a cluster of nodes that it can use to run containerized tasks. You tell Kubernetes how much CPU and memory (RAM) each container needs. Kubernetes can fit containers onto your nodes to make the best use of your resources.
- Self-healing Kubernetes restarts containers that fail, replaces containers, kills containers that don’t respond to your user-defined health check, and doesn’t advertise them to clients until they are ready to serve.
- Secret and configuration management Kubernetes lets you store and manage sensitive information, such as passwords, OAuth tokens, and SSH keys. You can deploy and update secrets and application configuration without rebuilding your container images, and without exposing secrets in your stack configuration.
What Kubernetes is not
Kubernetes is not a traditional, all-inclusive PaaS (Platform as a Service) system. Since Kubernetes operates at the container level rather than at the hardware level, it provides some generally applicable features common to PaaS offerings, such as deployment, scaling, load balancing, and lets users integrate their logging, monitoring, and alerting solutions. However, Kubernetes is not monolithic, and these default solutions are optional and pluggable. Kubernetes provides the building blocks for building developer platforms, but preserves user choice and flexibility where it is important.
Kubernetes:
- Does not limit the types of applications supported. Kubernetes aims to support an extremely diverse variety of workloads, including stateless, stateful, and data-processing workloads. If an application can run in a container, it should run great on Kubernetes.
- Does not deploy source code and does not build your application. Continuous Integration, Delivery, and Deployment (CI/CD) workflows are determined by organization cultures and preferences as well as technical requirements.
- Does not provide application-level services, such as middleware (for example, message buses), data-processing frameworks (for example, Spark), databases (for example, MySQL), caches, nor cluster storage systems (for example, Ceph) as built-in services. Such components can run on Kubernetes, and/or can be accessed by applications running on Kubernetes through portable mechanisms, such as the Open Service Broker.
- Does not dictate logging, monitoring, or alerting solutions. It provides some integrations as proof of concept, and mechanisms to collect and export metrics.
- Does not provide nor mandate a configuration language/system (for example, Jsonnet). It provides a declarative API that may be targeted by arbitrary forms of declarative specifications.
- Does not provide nor adopt any comprehensive machine configuration, maintenance, management, or self-healing systems.
- Additionally, Kubernetes is not a mere orchestration system. In fact, it eliminates the need for orchestration. The technical definition of orchestration is execution of a defined workflow: first do A, then B, then C. In contrast, Kubernetes comprises a set of independent, composable control processes that continuously drive the current state towards the provided desired state. It shouldn’t matter how you get from A to C. Centralized control is also not required. This results in a system that is easier to use and more powerful, robust, resilient, and extensible.
Share with your friends and followers
Start blogging about your favorite technologies, reach more readers and earn rewards!
Join other developers and claim your FAUN account now!

Mukul Attavania
Software Developer
@contactmukul95



User Popularity
47
Influence
5k
Total Hits
1
Posts




Read, Learn, Know, Teach
Hand curated newsletters for Developers, private Slack with like minded people, podcasts, job offers, news and more!

Only registered users can post comments. Please, login or signup.