







This blog gives an introduction of AWS Lake Formation service and describes how to setup AWS Lake Formation to enforce access controls that operate at the table, column, row, and cell-level for two users that access your data lake stored in S3. In this blog we will walk through the introduction, benefits, working and use cases of lake formation in AWS. Apart from this, we will see how to add a data lake in S3, create database and tables using AWS Glue and how to setup lake formation to order to enforce access controls that operate at the table, column, row, and cell-level for two users and query Athena to verify the results. This will reduce the effort in configuring policies across services and provides consistent enforcement and compliance.
What is AWS Lake Formation ?
AWS Lake Formation is a service that makes it easy to set up a secure data lake in days. A data lake is a centralised, curated, and secured repository that stores all your data, both in its original form and prepared for analysis. A data lake lets you break down data silos and combine different types of analytics to gain insights and guide better business decisions.
Setting up and managing data lakes today involves a lot of manual, complicated, and time-consuming tasks. This work includes loading data from diverse sources, monitoring those data flows, setting up partitions, turning on encryption and managing keys, defining transformation jobs and monitoring their operation, re-organising data into a columnar format, deduplicating redundant data, and matching linked records. Once data has been loaded into the data lake, you need to grant fine-grained access to datasets, and audit access over time across a wide range of analytics and machine learning (ML) tools and services.
Creating a data lake with Lake Formation is as simple as defining data sources and what access and security policies you want to apply. Lake Formation then helps you collect and catalog data from databases and object storage, move the data into your new Amazon Simple Storage Service (S3) data lake, clean and classify your data using ML algorithms, and secure access to your sensitive data using granular controls at the column, row, and cell-levels. Your users can access a centralised data catalog that describes available datasets and their appropriate usage. They then use these datasets with their choice of analytics and ML services, such as Amazon Redshift, Amazon Athena, Amazon EMR for Apache Spark, and Amazon QuickSight. Lake Formation builds on the capabilities available in AWS Glue.
Benefits of AWS Lake Formation
Build data lakes quickly
With Lake Formation, you can move, store, catalog, and clean your data faster. You simply point Lake Formation at your data sources, and it crawls those sources and moves the data into your new Amazon S3 data lake. Lake Formation organises data in S3 around frequently used query terms and into right-sized chunks to increase efficiency. It also changes data into formats such as Apache Parquet and ORC for faster analytics. In addition, Lake Formation has built-in ML to deduplicate and find matching records (two entries that refer to the same thing) to increase data quality.
Simplify security management
Lake Formation provides a single place to define and enforce access controls that operate at the table, column, row, and cell-level for all the users and services that access your data. Your policies are consistently implemented, eliminating the need to manually configure them across security services such as AWS Identity and Access Management (IAM) and AWS Key Management Service (KMS), storage services such as S3, and analytics and ML services such as Redshift, Athena, AWS Glue, and EMR for Apache Spark. This reduces the effort in configuring policies across services and provides consistent enforcement and compliance.
Provide self-service access to data
With Lake Formation, you build a data catalog that describes the different datasets available, along with which groups of users have access to each. This makes your users more productive by helping them find the right dataset to analyse. By providing a catalog of your data with consistent security enforcement, Lake Formation makes it easier for your analysts and data scientists to use their preferred analytics service. They can use EMR for Apache Spark, Redshift, Athena, AWS Glue, and Amazon QuickSight on diverse datasets now housed in a single data lake. Users can also combine these services without having to move data between silos.
Working of AWS Lake Formation
Lake Formation helps to build, secure, and manage your data lake. First, identify existing data stores in S3 or relational and NoSQL databases, and move the data into your data lake. Then crawl, catalog, and prepare the data for analytics. Next, provide your users with secure self-service access to the data through their choice of analytics services.
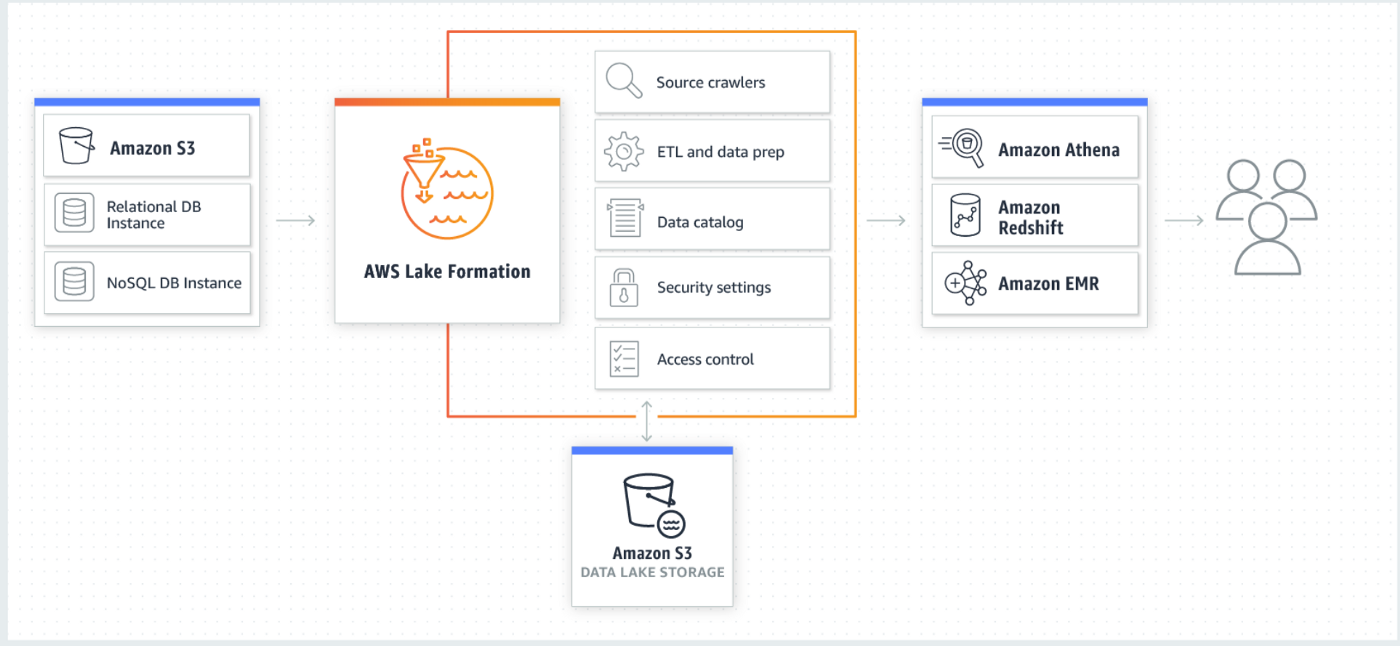
Other AWS services and third-party applications can also access data through the services shown. Lake Formation manages all of the tasks shown in the orange box and is integrated with the data stores and services shown in the blue boxes.
Use Cases
Build data lakes quickly
Use blueprints in Lake Formation to move, store, catalog, clean, and organise your data faster. Convert data into formats such as Parquet and ORC for faster analytics, and use built-in ML to de-duplicate and find matching records. Simplify how you store and maintain your data using Governed Tables, a new type of Amazon S3 table. Governed Tables use ACID (atomic, consistent, isolated, and durable) transactions that automatically manage conflicts and ensure consistent data views for all users. Governed Tables also monitor and automatically optimises your data to improve engine performance when querying the Governed Tables.
Centrally define and manage access controls
Lake Formation provides a single place to define, classify, tag, and manage fine-grained permissions for data in Amazon S3. You can define a hierarchical list of tags, assign tags to databases, tables and columns, and configure column and cell-level security.
Enforce data classification and fine-grained access
Lake Formation enforces policies without having to configure data access controls in each consuming service. Lake Formation automatically filters data and only reveals data permitted by the defined policy to authorised users, without having to duplicate data.
Enable continuous data management, time travel, and storage optimisation
Enhance data lake reliability and trustworthiness for updating batch and streaming data. Query historical data versions and audit changed data. Auto-compact small files and enable push-down filters to reduce data scans and improve query performance.
Enable federated data lakes with cross-account sharing
Deliver decentralised, domain-oriented data products across your organisation using well-governed data sharing with minimal to no data movement.
Walkthrough (Getting started with AWS Lake Formation)
In this walkthrough, I show you how to build and use a data lake. We would be completing the following activities to setup the lake formation in AWS—
- Create a data lake administrator.
- Register an Amazon S3 path.
- Create a database.
- Grant permissions.
- Crawl the data with AWS Glue to create the metadata and table.
- Grant access to the table data.
- Query the data using Amazon Athena.
- Add a new user with restricted access and verify the results.
Step 1: Create a data lake administrator
First, designate yourself a data lake administrator to allow access to any Lake Formation resource or create a new IAM User and designate it as a data lake administrator. We have created a new IAM user with the AWSLakeFormationDataAdmin and AdministratorAccess policy.

Step 2: Register an Amazon S3 path
Next, register an Amazon S3 path to contain your data in the data lake. Just for POC purpose we have created an S3 bucket called datalake-demographic and a folder named zipcode within the new S3 bucket.

Step 3: Upload a csv files in the S3 Bucket
Next, we must download the sample dataset and upload it. For this walkthrough, I use a table of City of New York statistics. Upload the file Demographics Statistics by Zip to your S3 bucket in the /zipcode folder.

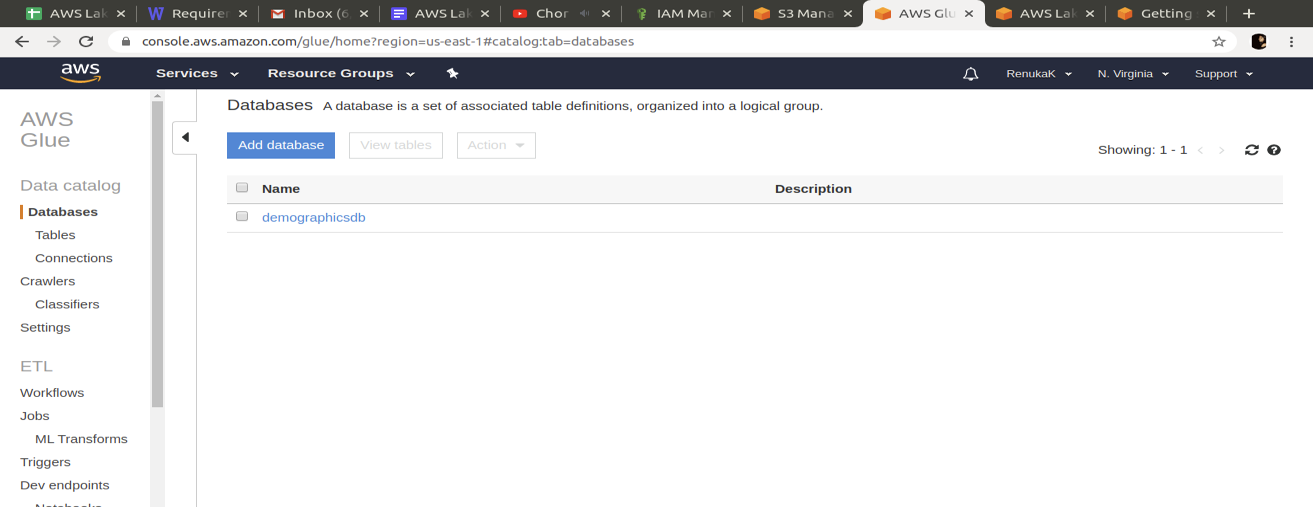
Step 4: Create a database in AWS Glue
Next, create a database in the AWS Glue Data Catalog to contain the zipcode table definitions.
- For Database, enter demographicsdb.
- For Location, enter your S3 bucket/zipcode.
Step 5: Crawl the data with AWS Glue to create the metadata and table
In this step, a crawler connects to a data store, progresses through a prioritised list of classifiers to determine the schema for your data, and then creates metadata tables in your AWS Glue Data Catalog.
Create a table using an AWS Glue crawler. Use the following configuration settings —
- Crawler name: zipcodecrawler.
- Data stores: Select this field.
- Choose a data store: Select S3.
- Specified path: Select this field.
- Include path: s3://datalake-demographic/zipcode.
- Add another data store: Choose No.
- Choose an existing IAM role: Select this field.
- IAM role: Select AWSGlueServiceRoleDefault.
- Run on demand: Select this field.
- Database: Select demographicsdb.
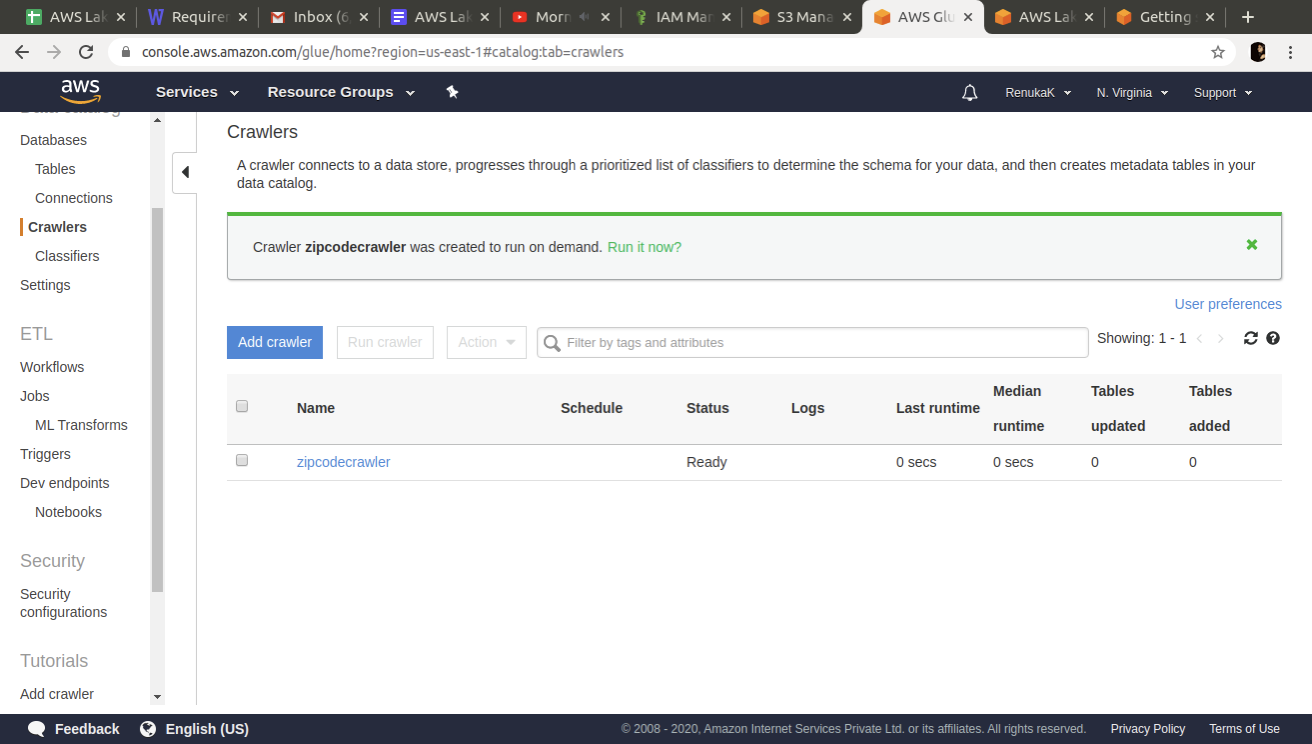
Run the crawler to create the table schema and wait for the crawler to stop before moving to the next step. To cross verify if the table has been created or not, go to AWS Data Glue table section and see the results.


Step 6: Query the data with Athena
Next, query the data in the data lake using Athena. Follow the steps below —
- In the Athena console, choose Query Editor and select the demographicsdb
- Choose Tables and select the zipcode table.
- Choose Table Options (three vertical dots to the right of the table name).
- Select Preview table.
Athena issues the following query:
SELECT * FROM “demographicsdb”.”zipcode” limit 10;
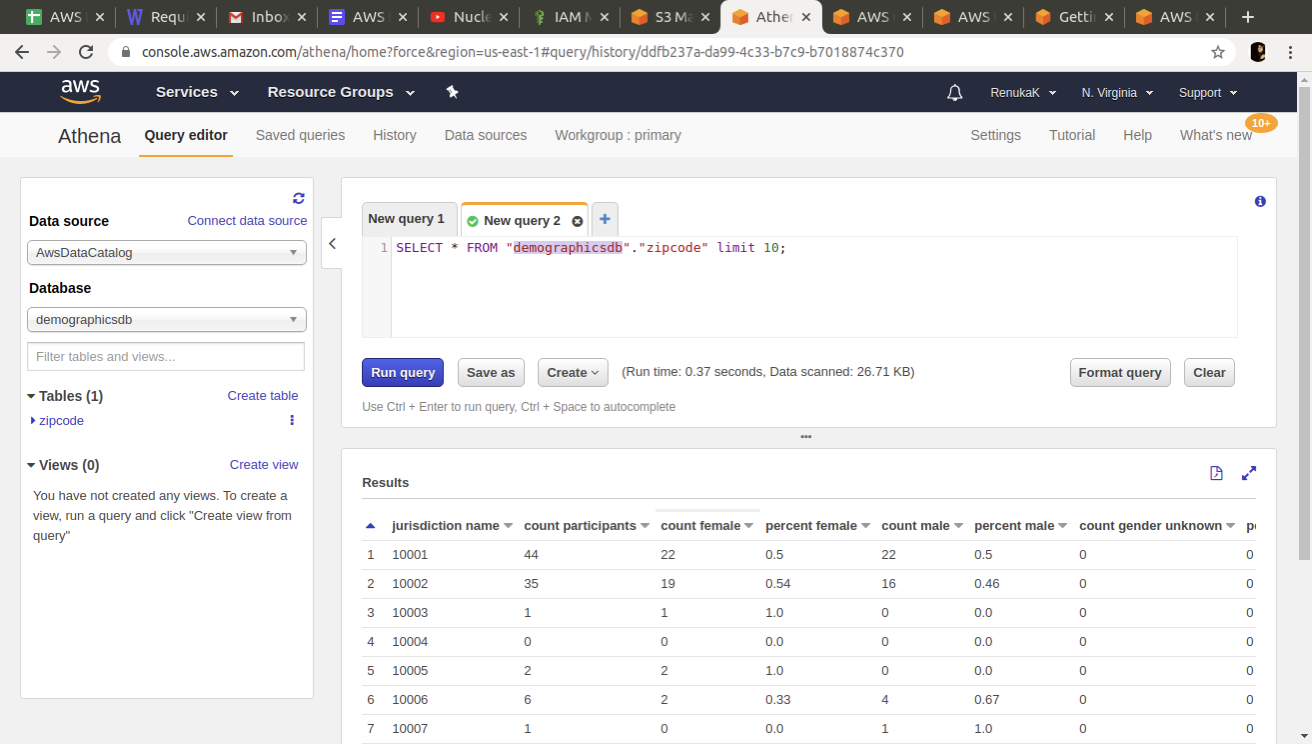
As you can see from the above screenshot that the user can see all of the columns of the table as we did not enable the AWS Lake Formation yet.
Step 7: Create new IAM user to restrict access to specific columns in the table
In the IAM console, create two IAM users called user1 and user2 with administrative rights and add AWSLakeFormationDataAdmin policy.


Step 8: Register S3 location in AWS Lake Formation
Before getting started we need to register the S3 location in Lake Formation. In the Lake Formation console, to register S3 location, supply the following configuration settings:
- Amazon S3 path: : s3://datalake-demographic
- IAM Role: AWSServiceRoleForLakeFormationDataAccess

Step 9: Add a new user with restricted access and verify the results
This step shows how you, as the data lake administrator, can set up a user with restricted access to specific columns. Login using datalakeadmin user to grant restricted permissions to the newly created user in step 8.
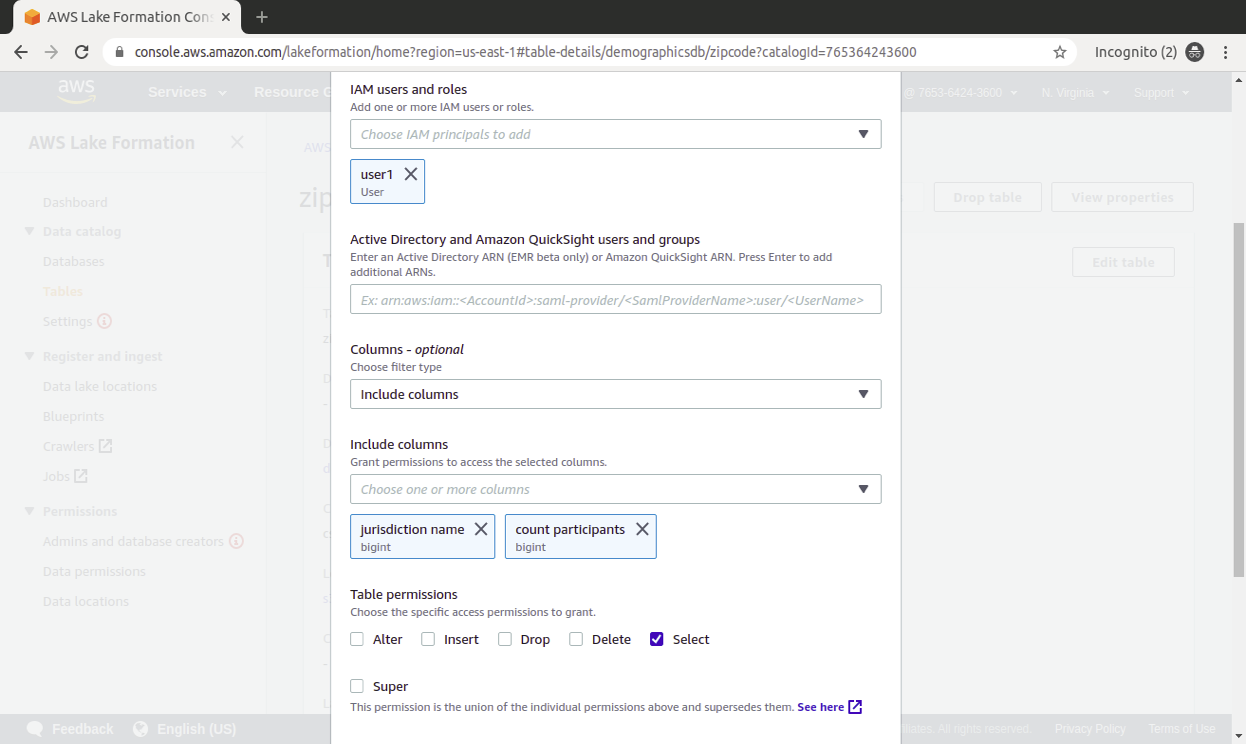
In the Lake Formation console, grant permissions to user1, go to table and select Grants in Action and supply the following configuration settings:
- Database: Select demographicsdb.
- Table: Select zipcode.
- Columns: Choose The include columns.
- The include columns: Choose Jurisdiction name and Count participants.
- Table permissions: Select.
For user2, we want to grant select permissions to all the columns, so go to AWS Lake Formation console, grant permissions to user2 and supply the following configuration settings:
- Database: Select demographicsdb.
- Table: Select zipcode.
- Table permissions: Select.

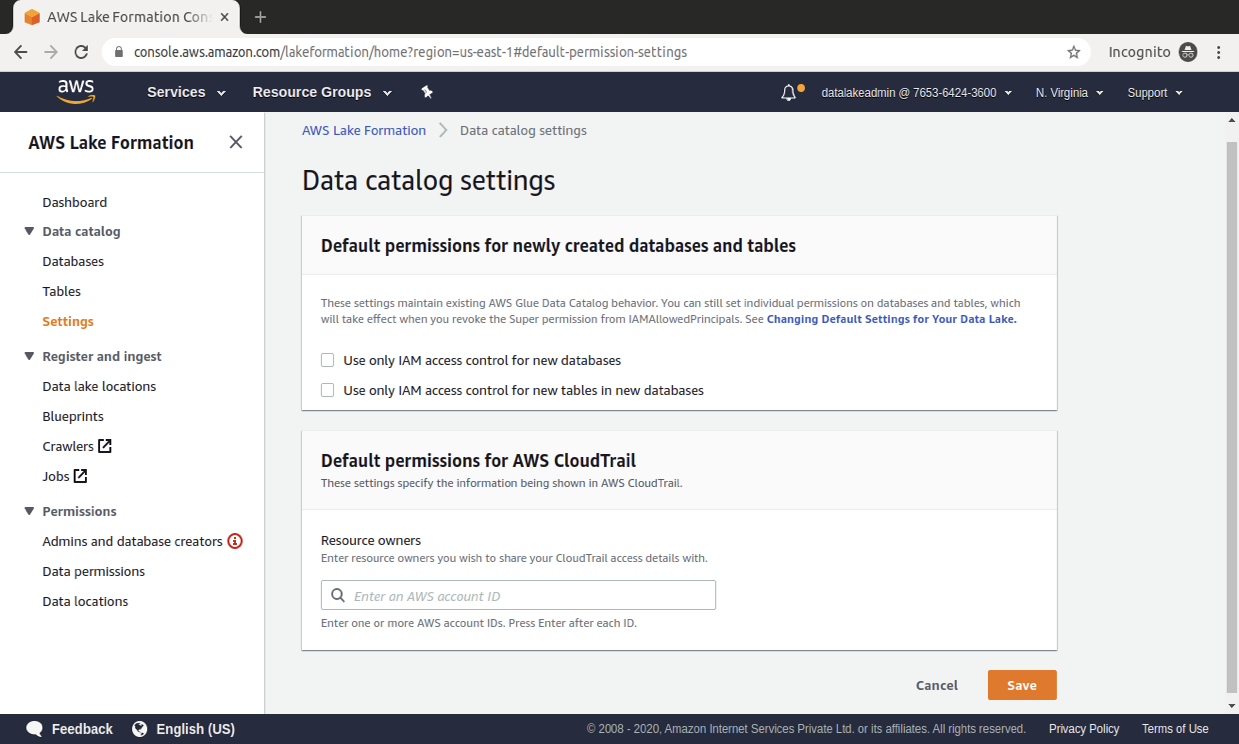
Step 10: Revoke default AWS Glue Catalog behaviour
This step shows how to revoke default Glue Catalog behaviour in order to enable AWS Lake formation. Uncheck both the check box in Data Catalog settings in Lake formation else these settings maintain existing AWS Glue Data Catalog behaviour.
Step 11: Revoke IAMAllowedPrincipals
This step shows how to revoke permission for default IAMAllowedPrincipals. You can still set individual permissions on databases and tables, which will take effect when you revoke the super permission from IAMAllowedPrincipals.
Go to AWS lake formation console then data permissions. Select the IAMAllowedPrincipals and click on Revoke on top right side. Select all the permissions which it has and click on revoke. Similarly revoke the IAMAllowedPrincipals grants on tables as shown in the image given below —


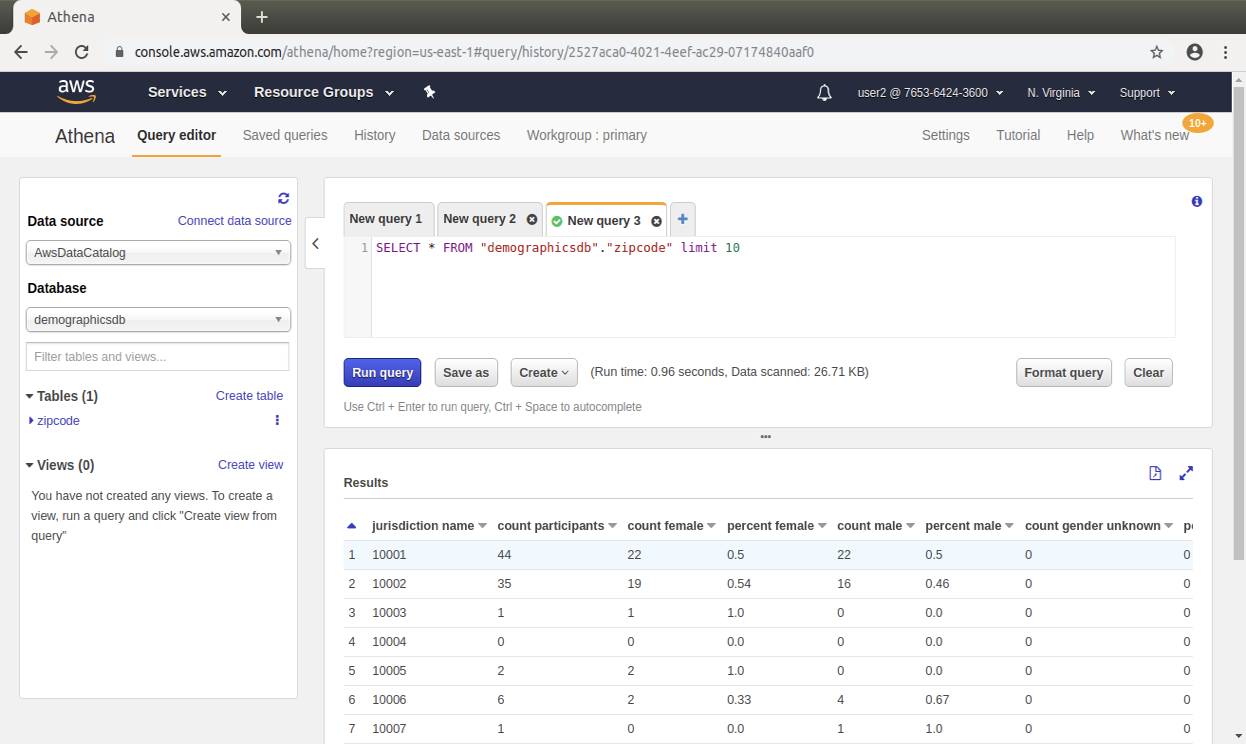
Step 12: Verifying the restricted access of each user
To verify the results of the restricted permissions, repeat step 6 when you are logged in as user1. As shown in the image given below, user1 can only see columns (jurisdiction name, count participant) that the datalakeadmin user granted them permissions to view.

Similarly login as user2 and repeat step 6. As the following screenshot shows, user2 can see all the columns that the datalakeadmin user granted them permissions to view.
Cheers !!! Finally you have completed the setup of AWS Lake Formation….
Conclusion
In this blog, we have introduced AWS lake formation, its benefits, working and use cases. Apart from this, we have shown how to add a data lake in S3, create database and tables using AWS Glue and how to setup lake formation to order to enforce access controls that operate at the table, column, row, and cell-level for two users and then query Athena to verify the results for each user. Lake Formation is implemented in order to reduce the effort in configuring policies across services and provides consistent enforcement and compliance.
Official Link — https://aws.amazon.com/lake-formation
Please reach me out on LinkedIn if you have any doubts and do not forget to follow me on Medium.
Thank you for reading. :)
Share with your friends and followers
Start blogging about your favorite technologies, reach more readers and earn rewards!
Join other developers and claim your FAUN account now!

Kumari Renuka
Cloud Architect, google
@renukachaubey24




User Popularity
37
Influence
4k
Total Hits
1
Posts


Read, Learn, Know, Teach
Hand curated newsletters for Developers, private Slack with like minded people, podcasts, job offers, news and more!

Only registered users can post comments. Please, login or signup.