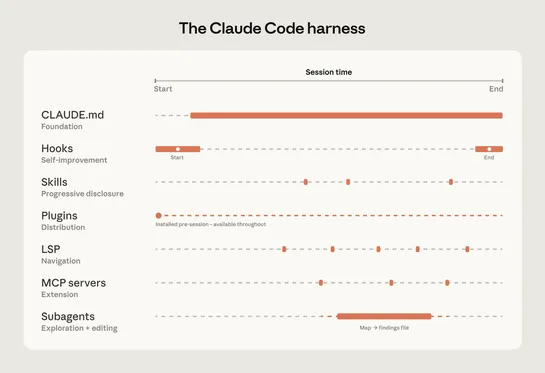
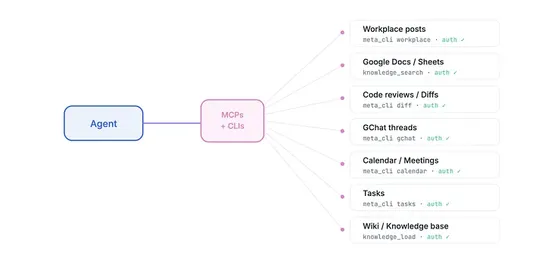
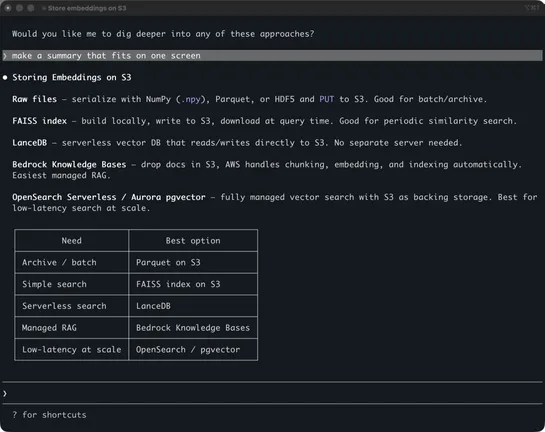
Claude’s next enterprise battle is not models: it’s the agent control plane
New data shows Microsoft and OpenAI leading agent orchestration, but Anthropic's rising stake signals a shift in control of AI infrastructure. Anthropic's move from model to orchestration layer hints at a strategic battle over agent runtime platforms where operational AI work happens... read more