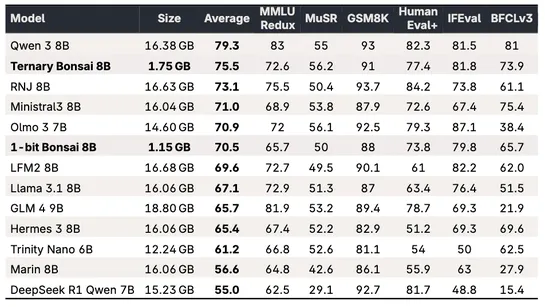
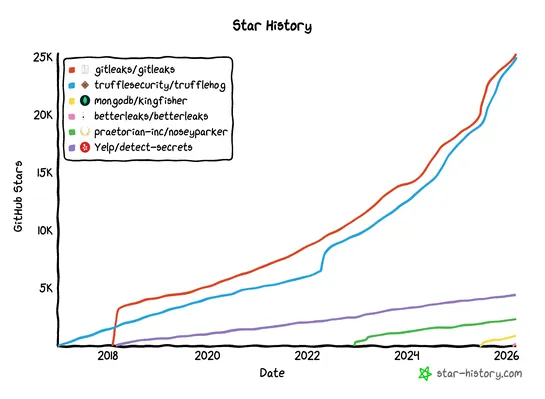
The AI-driven shift in vulnerability discovery: What maintainers and bug finders need to know
AI modelslet non-experts craft real and fake vulnerabilities at scale. They spit out low-quality noise and the occasional high-value report. Reports floodOSS maintainers. Triage, patching, release cadences, and downstreamupgrade/compliancepipelines buckle under the load. Guidance recommends publishi.. read more