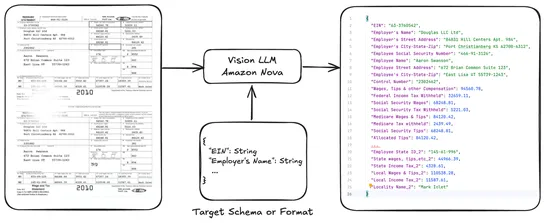
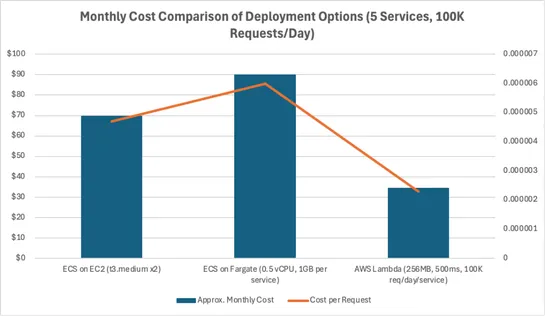
7 Common Kubernetes Pitfalls (and How I Learned to Avoid Them)
Seven ways folks trip over Kubernetes - each more avoidable than the last. Top offenses: skippingresource requests/limits, forgettinghealth probes, trustingephemeral logsthat vanish when you need them. Reusing configs across dev and prod? Still a bad idea. Pushing off observability until it’s on fir.. read more