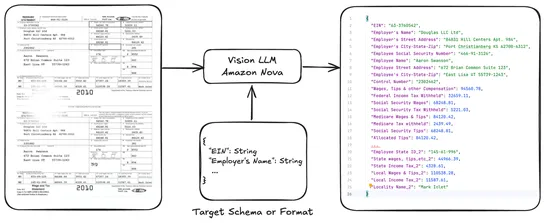
How to manage EKS Pod Identities at scale using Argo CD and AWS ACK
AWS shows how to wire upArgo CDwithAWS Controllers for Kubernetes (ACK)to automateEKS Pod Identityfor IAM roles - GitOps-style. The catch? The Pod Identity API has a lag. So they bolt on apre-deployment validation jobto wait-and-confirm that the IAM role's actually bound before app pods come online... read more