How Cloudways is manages its 90K servers fleet using Agentic SRE
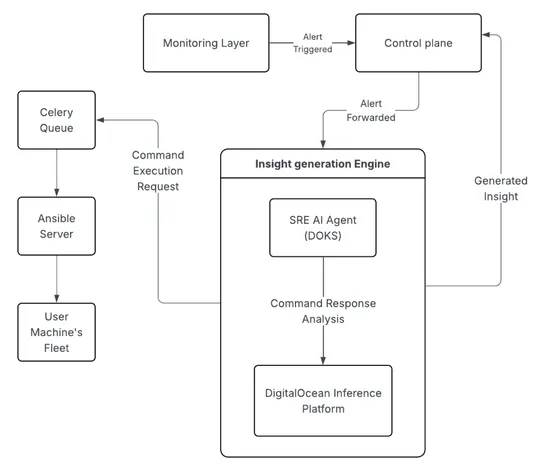
Scaling Autonomous Site Reliability Engineering: Architecture, Orchestration, and Validation for a 90,000+ Server Fleet
Join us

Scaling Autonomous Site Reliability Engineering: Architecture, Orchestration, and Validation for a 90,000+ Server Fleet


Anthropic's global AI study surveyed 80,508 participants across 159 countries, revealing desires for more personal time and concerns about AI's unreliability and job displacement. Sentiments vary regionally, with lower-income countries seeing AI as an equalizer, while Western Europe and North America focus on governance issues. The study highlights a complex mix of hope and fear regarding AI's impact.

At Slack, notifications were redesigned to address the overwhelming noise issue by simplifying choices and improving controls. The legacy system had complex preferences that made it difficult for users to understand and control notifications. Through a collaborative effort, the team refactored prefe.. read more
On March 9, 2026 a former maintainer grabbed the PyPI package forMkDocs. The original author's rights got stripped. Ownership snapped back within six hours. Core development stalled for 18 months.Material for MkDocswent into maintenance. The ecosystem splintered intoProperDocs,MaterialX, andZensical.. read more
AI systems are acting with more autonomy in real-world settings, with OpenAI focusing on responsibly navigating this transition to AGI by building capable systems and developing monitoring methods to deploy and manage them safely. OpenAI has implemented a monitoring system for coding agents to learn.. read more

In a world where the machine writes most of the code, Python lacks solid type enforcement, Rust is overly strict with complex lifetimes, while Go strikes the right balance by catching critical issues without hindering development velocity. The article argues in favor of Go over Python and Rust for A.. read more

The Python ecosystem's insistence on solving multiple problems when distributing functions has led to unnecessary complexity. The dominant frameworks have fused orchestration into the execution layer, imposing constraints on function shape, argument serialization, control flow, and error handling. W.. read more

AWS ships GAGateway APIsupport in theAWS Load Balancer Controller. Teams can manageALBandNLBwith the SIG standard. The controller swaps annotation JSON for validated CRDs -TargetGroupConfiguration,LoadBalancerConfiguration,ListenerRuleConfiguration- and handles L4 (TCP/UDP/TLS) and L7 (HTTP/gRPC). M.. read more

Atlantis, a tool for planning and applying Terraform changes, faced slow restarts of up to 30 minutes due to a safe default in Kubernetes that became a bottleneck as the persistent volume used by Atlantis grew to millions of files. After investigation, a one-line change to fsGroupChangePolicy reduce.. read more


