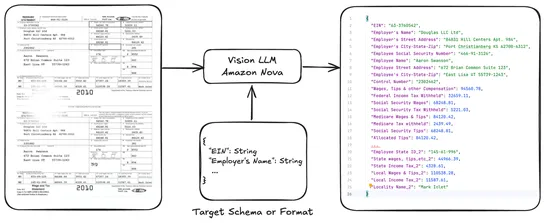
Replaying massive data in a non-production environment using Pekko Streams and Kubernetes Pekko Cluster
DoubleVerify built a traffic replay tool that actually scales. It runs onPekko StreamsandPekko Cluster, pumping real production-like traffic into non-prod setups. Throttlenails the RPS with precision for functional tests.Distributed datasyncs stressful loads across cluster nodes without breaking a s.. read more