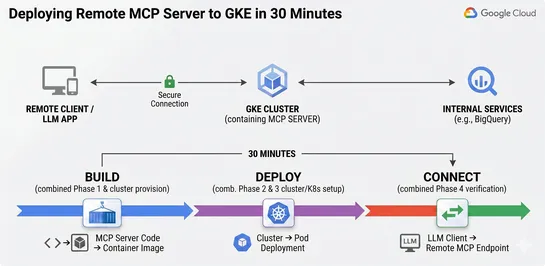
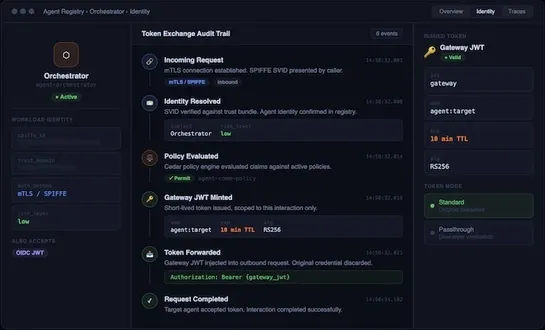
Build and Deploy a Remote MCP Server to GKE in 30 Minutes
Google walks you through shipping a remoteMCP serveronGKE AutopilotusingFastMCPandstreamable-http, swapping localstdiofor shared HTTP endpoints. The clever bit: theGateway APIhandles managed SSL plusCLIENT_IP session affinity, so one centralized server beats everyone running redundant local copies... read more