Effective Incident Postmortems: Learn from Every Outage
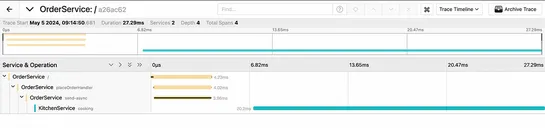
This blog post explains what incident postmortems are and why they are important. It details the steps involved in conducting an effective incident postmortem, including creating a timeline, holding a meeting, and capturing key details. The importance of a blameless environment is emphasized. The blog post concludes by recommending resources for further reading on the topic.