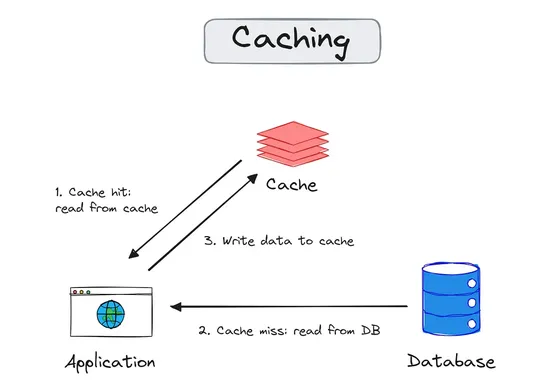
How In-Memory Caching Works in Redis
Redis isn’t just a cache anymore. Sure, it still owns the in-memory speed game—with **key expiration**, **data persistence**, and **horizontal scaling** via **replication** and **clustering**. But if you're only using it to stash a few keys, you're missing the point. This thing handles **streams**,.. read more