Link
@last9io shared a link, 2 years, 2 months ago
Last9
Activity
@kate_kucherniuk97 created an organization DevOpsDays Ukraine , 2 years, 2 months ago.
Link
@faun shared a link, 2 years, 2 months ago
FAUN.dev()
Azure Host OS Update with Hypervisor Hot Restart
Azure, Microsoft's cloud computing service, hosts millions of customer virtual machines and ensures their security and functionality through various update mechanisms, including Hypervisor Hot Restart (HHR). HHR allows the replacement of the hypervisor on a running system with sub-second blackout ti.. read more
Link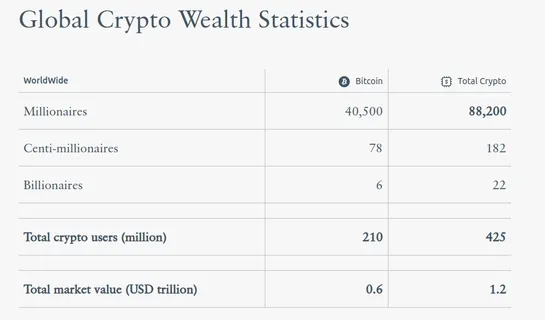
@faun shared a link, 2 years, 2 months ago
FAUN.dev()
Crypto Wealth Report 2023
Henley & Partners' inaugural publication provides exclusive statistics on crypto and Bitcoin millionaires, centi-millionaires, and billionaires, along with insights from leading experts and an innovative Crypto Adoption Index comparing investment migration programs for crypto investors... read more
Link
@faun shared a link, 2 years, 2 months ago
FAUN.dev()
Good relevance and outcomes for alerting and monitoring
Engineering organizations need to set up alerts based on actionable, relevant indicators, such as service-level indicators (SLIs) that matter to users, and these alerts should focus on symptoms users can feel. Alert policies should consider the severity, duration, and breadth of an issue, and notifi.. read more
Link
@faun shared a link, 2 years, 2 months ago
FAUN.dev()
Profile-guided optimization in Go 1.21
Profileguided optimization (PGO) in Go is a feature that allows the Go compiler to optimize a binary based on runtime profiling data. With PGO, the compiler can make informed decisions about which optimizations to apply, such as constant propagation, escape analysis, and devirtualization, resulting .. read more
Link
@faun shared a link, 2 years, 2 months ago
FAUN.dev()
CircleCI: Manage Kubernetes environments with GitOps and dynamic config
Learn how to leverage CircleCI’s dynamic configuration to provision and manage Kubernetes infrastructure in an automated, reliable, and resource-efficient way... read more
Link
@faun shared a link, 2 years, 2 months ago
FAUN.dev()
How to Deploy Auto-Scalable Gitlab Runners in AWS Using Packer, Terraform, and Ansible
A step-by-step guide on how to provision highly scalable specific runners in AWS using Packer, Ansible, and Terraform.. read more
Link
@faun shared a link, 2 years, 2 months ago
FAUN.dev()
How Amazon.com Search Uses Chaos Engineering to Handle Over 84K Requests Per Second
Chaos engineering is used by Amazon's search team to ensure resilience and improve their search service. They use chaos experiments to understand how their application reacts to faults and loads, and to make necessary improvements to its resilience... read more
Link
@faun shared a link, 2 years, 2 months ago
FAUN.dev()
Why is logging so damn hard?
Logs are usually plain chaos, but why? In this post, the author shares what they learned doing logging wrong, and how you can start improving your logging practices today... read more

