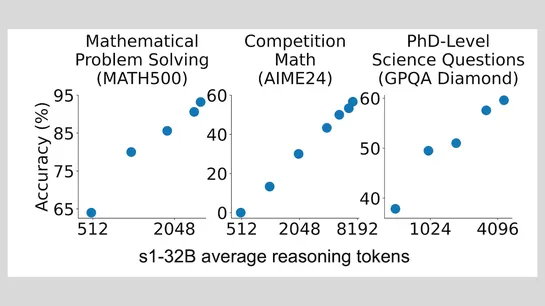
Researchers Fine-Tune LLM for Reasoning with Only 1,000 Examples
Meet the"Wait" token trick—a clever nudge that sharpens a model's reasoning. It mirrors OpenAI's o1-preview magic using only 1,000 examples. And guess what? Not a speck of reinforcement learning in sight... read more