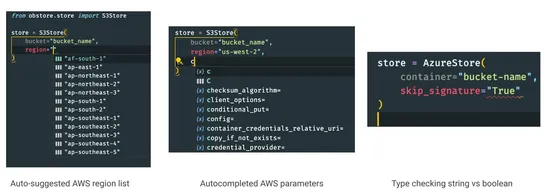
🚀 Strengthening Europe’s Cybersecurity in Space
Just in case you missed it last month: The European Space Agency (ESA) has launched its brand-new Cybersecurity Operations Center (C-SOC) to safeguard satellites, mission control systems, and digital assets against growing cyber threats. 🌍 In today’s space-driven world, initiatives like this — suppo..