How We Built an AI Second Brain for 60K Knowledge Workers
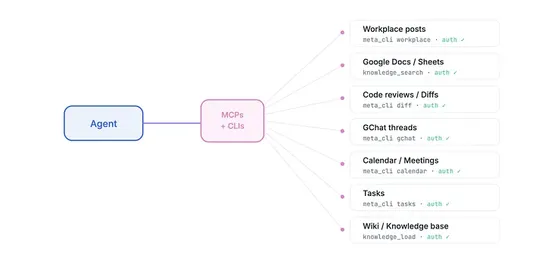
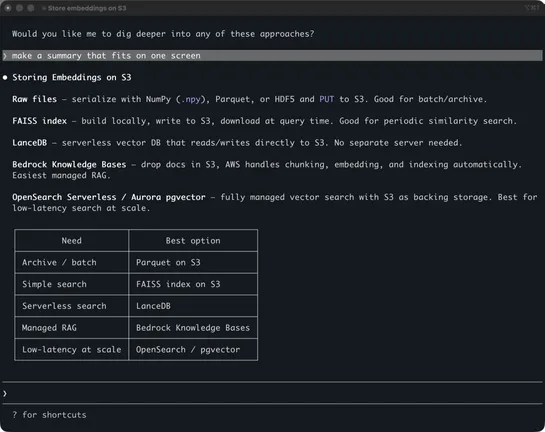
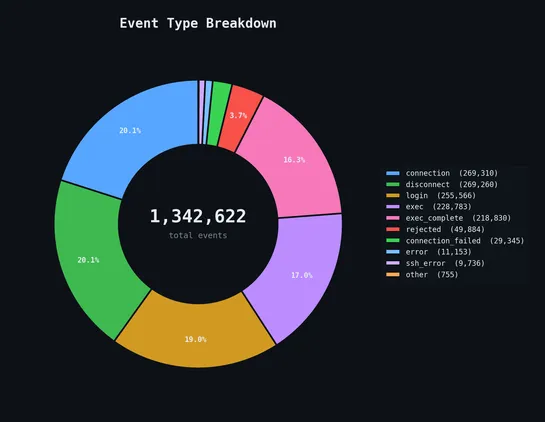
Meta built an AI agent system internally called the AI Second Brain that now has over 63,000 installs and ~10,000 daily active users across engineering, PM, design, legal, finance, comms, and sales, growing from zero in roughly three months after a non-technical PM's adoption post. The architecture .. read more