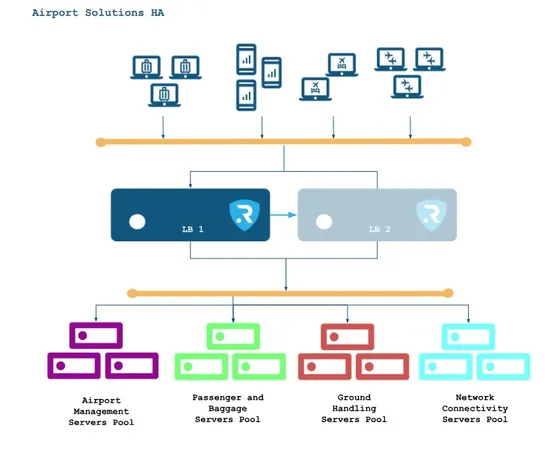
𝗗𝘂𝗯𝗹𝗶𝗻 𝗧𝗲𝗰𝗵 𝗦𝘂𝗺𝗺𝗶𝘁 𝟮𝟬𝟮𝟲
Excited to announce that 𝗥𝗘𝗟𝗜𝗔𝗡𝗢𝗜𝗗 will be attending the 𝗗𝘂𝗯𝗹𝗶𝗻 𝗧𝗲𝗰𝗵 𝗦𝘂𝗺𝗺𝗶𝘁 𝟮𝟬𝟮𝟲 on May 27–28 in Dublin! Celebrating its 10th anniversary, this global tech event brings together innovators, startups, investors, and industry leaders from over 70 countries to 𝘦𝘹𝘱𝘭𝘰𝘳𝘦 𝘵𝘩𝘦 𝘧𝘶𝘵𝘶𝘳𝘦 𝘰𝘧 𝘵𝘦𝘤𝘩𝘯𝘰𝘭𝘰𝘨𝘺. 🚀 From A..