






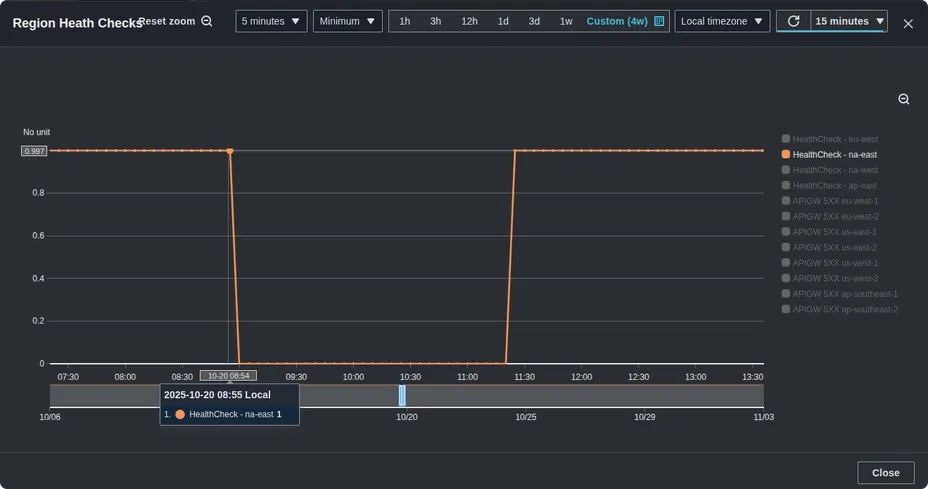
During the AWS us-east-1 meltdown - when DynamoDB, IAM, and other key services went dark - Authress kept the lights on. Their trick? A ruthless edge-first, multi-region setup built for failure.
They didn’t hope DNS would save them. They wired in automated failover, rolled their own health checks, and watched business metrics - not just system metrics - for signs of trouble. That combo? It worked.
To chase a 99.999% SLA, they stripped out weak links, dodged flaky third-party services, and made all compute region-agnostic. DynamoDB Global Tables handled global state. CloudFront + Lambda@Edge took care of traffic sorcery.
The bigger picture: Reliability isn’t a load balancer’s job anymore. It starts in your architecture. Cloud provider defaults? Not enough. Build like you don’t trust them.


