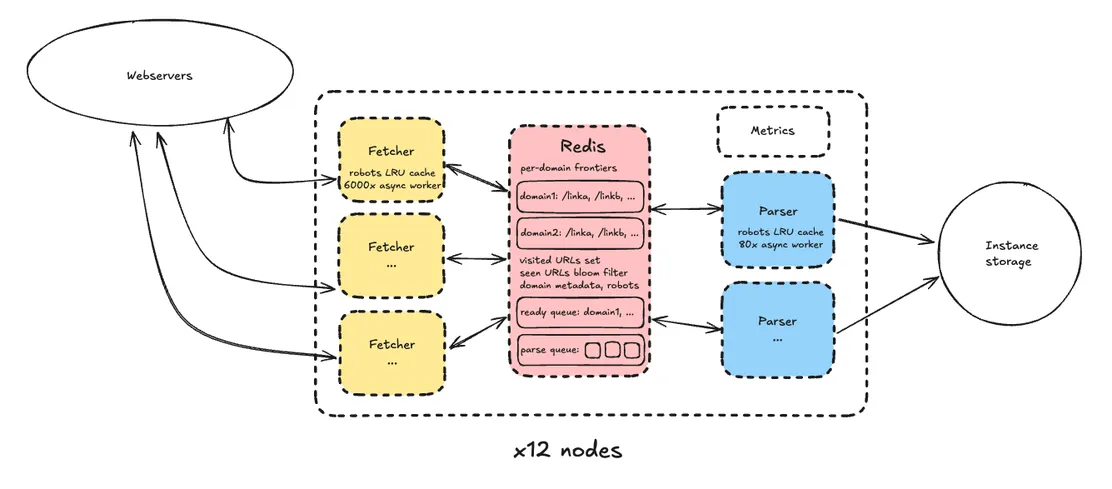
Imagine tearing through 1 billion pages in a single day on a shoestring budget. This crawler pulled it off with 12 nodes and some savvy async maneuvering. But here's the kicker: it wasn’t the fetching that choked the CPU. Nope, it was the parsing. Today’s web behemoths, bloated with JavaScript and other digital detritus, laugh at good old HTML parsers. So, if dynamic rendering gets on your to-do list, brace for sticker shock.







Give a Pawfive to this post!
Share with your friends and followers
Start writing about what excites you in tech — connect with developers, grow your voice, and get rewarded.
Join other developers and claim your FAUN.dev() account now!








