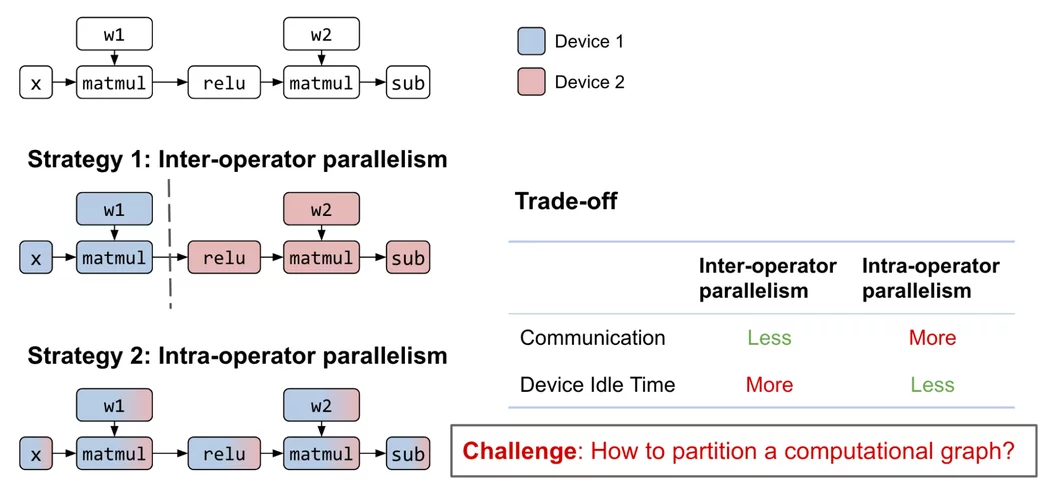
This post presents how two open-source frameworks, Alpa.ai and Ray.io, work together to achieve the scale required to train a 175 billion-parameter JAX transformer model with pipeline parallelism. They enable the training of LLMs on large GPU clusters, automatically parallelizing computations and optimizing performance. The frameworks use techniques like interoperator and intraoperator parallelism and provide abstractions for GPU device management and communication.







Give a Pawfive to this post!
Share with your friends and followers
Start writing about what excites you in tech — connect with developers, grow your voice, and get rewarded.
Join other developers and claim your FAUN.dev() account now!








