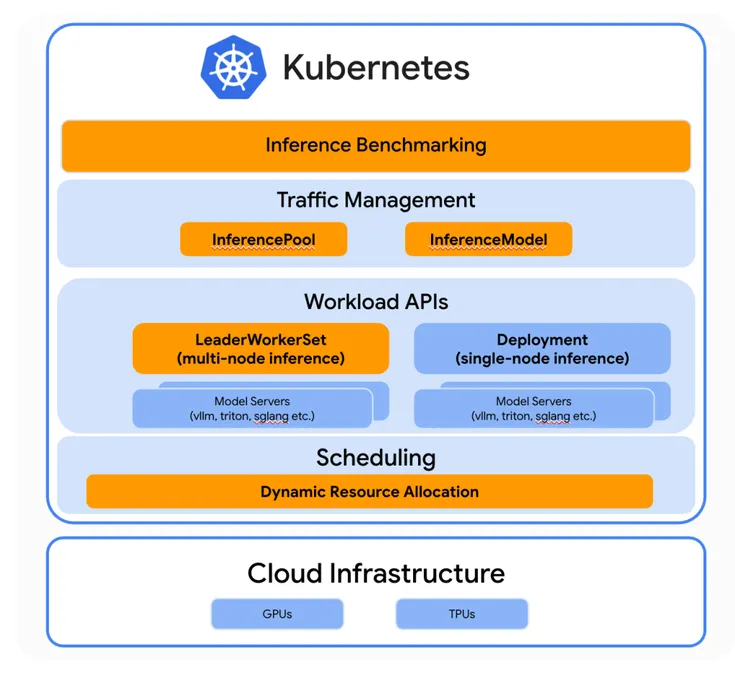
Google Cloud, ByteDance, and Red Hat are wiring AI smarts straight into Kubernetes. Think: faster inference benchmarks, smarter LLM-aware routing, and on-the-fly resource juggling—all built to handle GenAI heat.
Their new push, llm-d, bakes vLLM deep into Kubernetes. That unlocks disaggregated serving and cluster-wide KV cache tuning. Translation: serving LLMs just got leaner and meaner.
Big picture: Kubernetes isn't just for microservices anymore. It's turning into an AI-native runtime—purpose-built to wrangle large models at scale.







Give a Pawfive to this post!
Share with your friends and followers
Start writing about what excites you in tech — connect with developers, grow your voice, and get rewarded.
Join other developers and claim your FAUN.dev() account now!








