






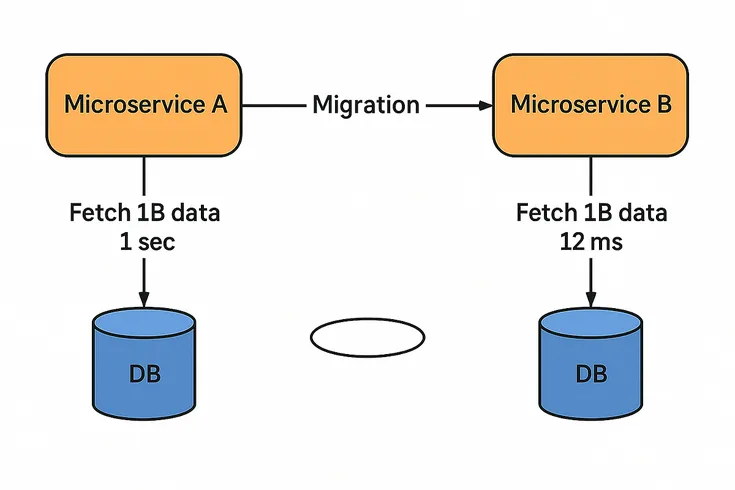
A team moved over 1 billion production records, no downtime, no drama. The stack: dual writes, Kafka retries, and idempotent inserts to keep it clean.
They ran shadow reads to sniff for errors, chunked the transfers with checksums, and held off indexing to keep inserts fast. Caches got warmed early to dodge cold start thrash.


