Learn how to speed up training of PyTorch and Hugging Face models using a reduction server through Vertex AI feature, optimizing bandwidth and latency to distribute training across multiple Nvidia GPUs.
The all-reduce based algorithm synchronously averages gradients across multiple devices, reducing training time and costs.
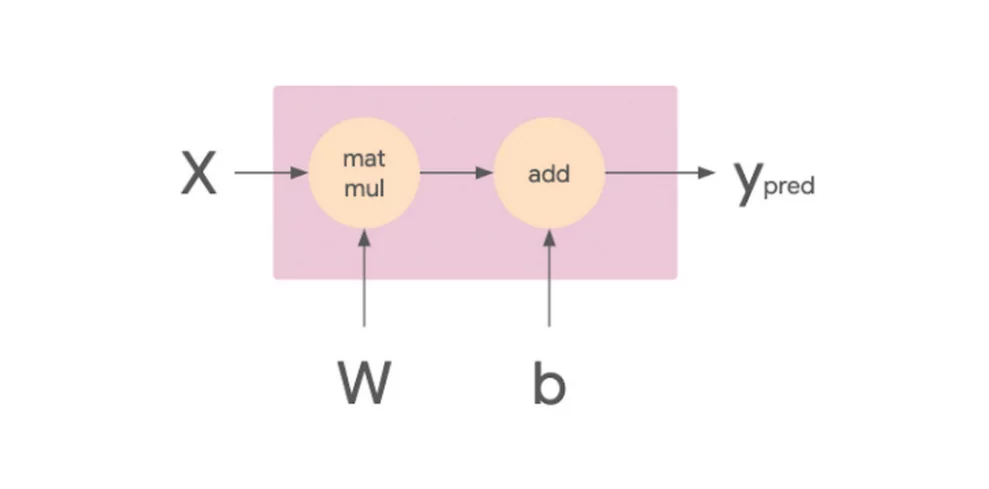
The post dives into a detailed description of datum parallelism and reduction server's architecture and impact on training throughput.
>>Check out the accompanying notebook and video to learn more!







Give a Pawfive to this post!
Share with your friends and followers
Start writing about what excites you in tech — connect with developers, grow your voice, and get rewarded.
Join other developers and claim your FAUN.dev() account now!








