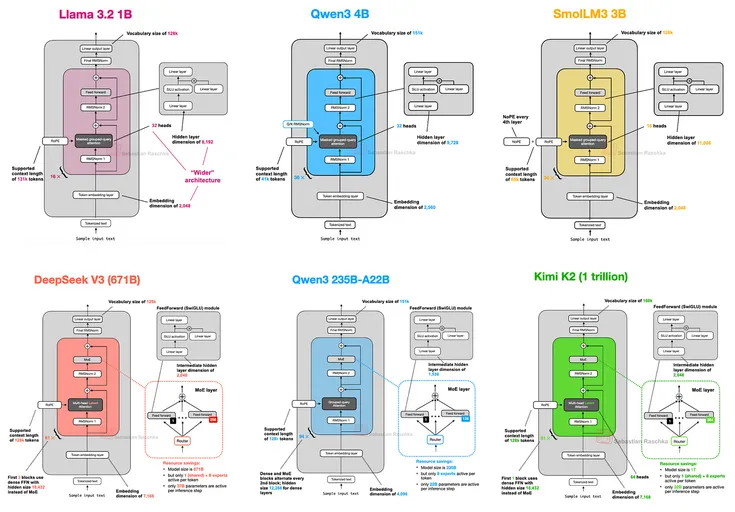
Architectures since GPT-2 still ride transformers. They crank memory and performance with RoPE, swap GQA for MLA, sprinkle in sparse MoE, and roll sliding-window attention. Teams shift RMSNorm. They tweak layer norms with QK-Norm, locking in training stability across modern models.
Trend to watch: In 2025, fine-grained efficiency hacks dethrone sweeping architecture overhauls.







Give a Pawfive to this post!
Share with your friends and followers
Start writing about what excites you in tech — connect with developers, grow your voice, and get rewarded.
Join other developers and claim your FAUN.dev() account now!








