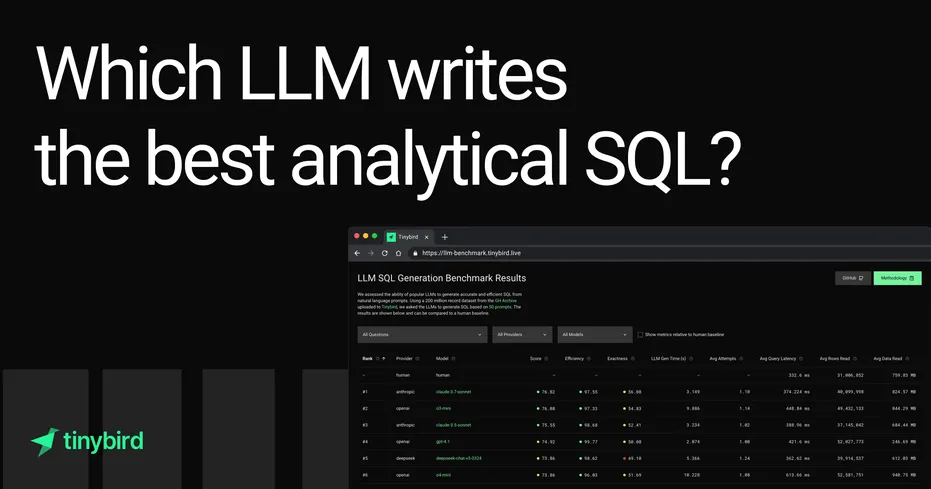
Tinybird threw 19 top LLMs at a 200M-row GitHub dataset, testing how well they could turn plain English into solid SQL. Most models kept their syntax clean—but when it came to writing SQL that actually ran well and returned the right results, they lagged behind human pros. Messy schemas or tricky prompts? Total tripwire.







Give a Pawfive to this post!
Share with your friends and followers
Start writing about what excites you in tech — connect with developers, grow your voice, and get rewarded.
Join other developers and claim your FAUN.dev() account now!








