






TL;DR
Google successfully operates a 130,000-node Kubernetes cluster to enhance GKE's scalability for AI workloads.
Key Points
Highlight key points with color coding based on sentiment (positive, neutral, negative).Google Kubernetes Engine (GKE) has been scaled to support a 130,000-node cluster, doubling the previously supported limit, to meet the demands of large AI workloads.
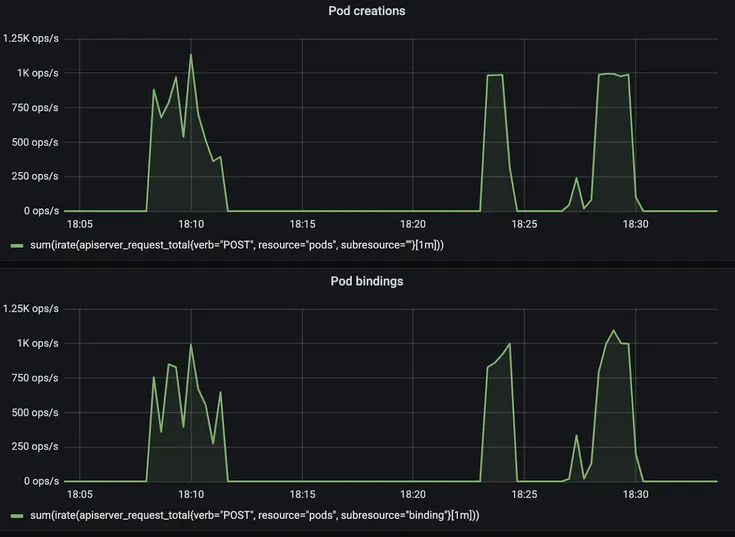
Key architectural innovations were necessary for this scalability, including optimized Pod creation, scheduling throughput, and a strongly consistent API server watch cache to handle the high volume of read requests efficiently.
Power consumption is a significant challenge for large AI workloads, with a single NVIDIA GB200 GPU requiring 2700W.
The Consistent Reads from Cache feature improves API server performance by serving strongly consistent data directly from an in-memory cache, reducing the load on the central object datastore.
Smaller GKE customers benefit from these scalability improvements through enhanced system resilience, increased error tolerance, and optimized performance, even at more modest scales.
Google Cloud is making waves with its latest project: a colossal 130,000-node Google Kubernetes Engine (GKE) cluster. This isn't just a minor upgrade; it's a bold move to meet the surging demands of AI workloads. To pull this off, Google had to rethink some of its architectural strategies, focusing on boosting scalability by optimizing Pod creation and scheduling throughput. The cluster, still in its experimental phase, doubles the previous node limit of 65,000. But let's be real, scaling up to this magnitude isn't a walk in the park. Power consumption becomes a major concern, especially when a single NVIDIA GB200 GPU can gulp down 2700W. This could mean a power footprint that scales to hundreds of megawatts - quite the challenge.
To tackle these hurdles, Google Cloud is leaning on tools like MultiKueue, which aids in distributed training and reinforcement learning across clusters. They're also exploring high-performance RDMA networking and topology awareness to squeeze every bit of performance out of those hefty AI workloads. And here's the kicker: these improvements aren't just for the tech giants. Smaller GKE customers stand to benefit too, with improved system resilience and performance, thanks to fine-tuned core systems and a more intuitive, self-service experience.
One of the standout features in this architectural overhaul is the creation of a strongly consistent and snapshottable API server watch cache. This clever addition manages the high volume of read requests at scale. The Consistent Reads from Cache feature allows the API server to serve data directly from its in-memory cache, reducing the load on the object storage database. Meanwhile, the Snapshottable API Server Cache feature boosts performance by letting the API server serve LIST requests for previous states straight from the cache.
Backing this massive scale is a proprietary key-value store based on Google’s Spanner distributed database, handling 13,000 QPS to update lease objects, ensuring stability and reliability. Kueue, a job queueing controller, steps in to provide advanced job-level management for complex AI/ML environments, enabling efficient orchestration of training, batch, and inference workloads. Looking ahead, Kubernetes scheduling is set to evolve, shifting from a Pod-centric to a workload-centric approach to optimize price-performance for AI/ML workloads. Plus, GCS FUSE and Google Cloud Managed Lustre offer scalable, high-throughput data access solutions for AI workloads.
To verify GKE's performance, Google crafted a four-phase benchmark, simulating a dynamic environment with complex resource management and scheduling challenges. This included deploying a large-scale training workload to establish a performance baseline, revealing key metrics like Pod startup latency and scheduling throughput.
Key Numbers
Present key numerics and statistics in a minimalist format.The total number of nodes in the Google Kubernetes Engine (GKE) cluster.
The Pod throughput sustained during the experimental phase of the GKE cluster.
The total number of objects stored in the optimized distributed storage system of the GKE cluster.
Stakeholder Relationships
An interactive diagram mapping entities directly or indirectly involved in this news. Drag nodes to rearrange them and see relationship details.Organizations
Key entities and stakeholders, categorized for clarity: people, organizations, tools, events, regulatory bodies, and industries.Responsible for the architectural innovations and technical enhancements required to scale GKE to 130,000 nodes.
Plays a role in developing and maintaining the open-source components that GKE relies on for scalability.
Tools
Key entities and stakeholders, categorized for clarity: people, organizations, tools, events, regulatory bodies, and industries.The platform being scaled to support a 130,000-node cluster for large-scale AI workloads.
Industries
Key entities and stakeholders, categorized for clarity: people, organizations, tools, events, regulatory bodies, and industries.Drive the demand and use cases for massive clusters, particularly for AI workloads.
Timeline of Events
Timeline of key events and milestones.A blog post was published detailing the Consistent Reads from Cache feature (KEP-2340).
Google Kubernetes Engine (GKE) supports 65,000-node clusters, providing the capacity for demanding AI workloads.
Google shared the achievement of running a 130,000-node GKE cluster at KubeCon, doubling the previously supported 65,000-node limit
Additional Resources
Enjoyed it?
Get weekly updates delivered straight to your inbox, it only takes 3 seconds!Subscribe to our weekly newsletter Kaptain to receive similar updates for free!
Give a Pawfive to this post!
Share with your friends and followers
Start writing about what excites you in tech — connect with developers, grow your voice, and get rewarded.
Join other developers and claim your FAUN.dev() account now!
")
FAUN.dev()
FAUN.dev() is a developer-first platform built with a simple goal: help engineers stay sharp withou…







Kaptain #Kubernetes
FAUN.dev()
@kaptainDeveloper Influence
11
Influence
1
Total Hits
135
Posts
Related tools


Featured Course(s)


Cloud-Native Microservices With Kubernetes - 2nd Edition
A Comprehensive Guide to Building, Scaling, Deploying, Observing, and Managing Highly-Available Microservices in Kubernetes

End-to-End Kubernetes with Rancher, RKE2, K3s, Fleet, Longhorn, and NeuVector
The full journey from nothing to production
